GPT-5 non-thinking is labeled 52.8% accuracy, but o3 is shown as a much shorter bar, yet it's labeled 69.1%. And 4o is an identical bar to o3, but it's labeled 30.8%...
As someone who spent years quadruple checking every figure in every slide for years to avoid a mistake like this, it’s very confusing to see this out of the big launch announcement of one of the most high profile startups around.
Even the small presentations we gave to execs or the board were checked for errors so many times that nothing could possibly slip through.
I take a strange comfort in still spotting AI typos. Makes it obvious their shiny new "toy" isn't ready to replace professionals.
They talk about using this to help families facing a cancer diagnosis -- literal life or death! -- and we're supposed to trust a machine that can't even spot a few simple typos? Ha.
The lack of human proofreading says more about their values than their capabilities. They don't want oversight -- especially not from human professionals.
Cynically, the AI is ready to replace professionals, in areas where the stakeholders don't care too much. They can offer the services cheaper, and this is all that matters to their customers. Were it not so, companies like Tata won't have any customers. The phenomenon of "cheap Chinese junk" would not exist, because no retailer would order to produce it.
So, brace yourselves, we'll see more of this in production :(
Well, the world will split into those who care, and fields where precision is crucial, and the rest. Occasional mistakes are tolerable but systematic bullshit is a bit too much for me.
This separation (always a spectrum, not a split) already exists for a long time. Bouts of systemic bullshit occur every now and then, known as "bubbles" (as in dotcom bubble, mortgage bubble, etc) or "crises" (such as "reproducibility crisis", etc). Smaller waves rise and fall all the time, in the form of various scams (from the ancient tulip mania to Ponzi to Madoff to ICOs, etc).
It seems like large amounts of people, including people at high-up positions, tend to believe bullshit, as long as it makes them feel comfortable. This leads to various irrational business fashions and technological fads, to say nothing of political movements.
So yes, another wave of fashion, another miracle that works "as everybody knows" would fit right in. It's sad because bubbles inevitably burst, and that may slow down or even destroy some of the good parts, the real advances that ML is bringing.
I think this just further demonstrates the truth behind the truly small & scrappy teams culture at OpenAI that an ex-employee recently shared [1].
Even with the way the presenters talk, you can sort of see that OAI prioritizes speed above most other things, and a naive observer might think they are testing things a million different ways before releasing, but actually, they're not.
If we draw up a 2x2 for Danger (High/Low) versus Publicity (High/Low), it seems to me that OpenAI sure has a lot of hits in the Low-Danger High-Publicity quadrant, but probably also a good number in the High-Danger Low-Publicity quadrant -- extrapolating purely from the sheer capability of these models and the continuing ability of researchers like Pliny to crack through it still.
I don't think they give a shit. This is a sales presentation to the general public and the correct data is there. If one is pedantic enough they can see the correct number, if not it sells well. If they really cared grok etc. Would be on there too.
The opposite view is to show your execs the middle finger on nitpicking. Their product is definitely not more important than ChatGPT-5. So your typo does not matter. It didn't ever matter.
I don’t believe for mistake either. As others have said, these graphs are worth of billions. Everything is calculated. They take the risk that some will notice but most will not. They say that it is mistake for those who notice.
Not as much as current llms. But the point is that AIs are supposed to be better than us, kind of how people built calculators to be more reliable than the average person and faster than anyone.
Imagine we wouldn't tell criminals the law because they might try to find holes... This is just user-hostile and security through obscurity. If someone on HN knows that this is what is shown to banned people then so will the people that scrape or mean harm to imgur
In 2015, yes. In 2025? Probably not. Imgur is enshittifying rapidly since reddit started it's own image host. Lots of censorship and corporate gentrification. There's still some hangers on but it's a small group. 15 comments on imgur is a lot nowadays.
Why would you think it is anything special? Just because Sam Altman said so? The same guy who told us he was scared of releasing GPT-2.5 but now calling its abilities "toddler/kindergarten" level?
My comment was mostly a joke. I don't think there's anything "special" about GPT-5.
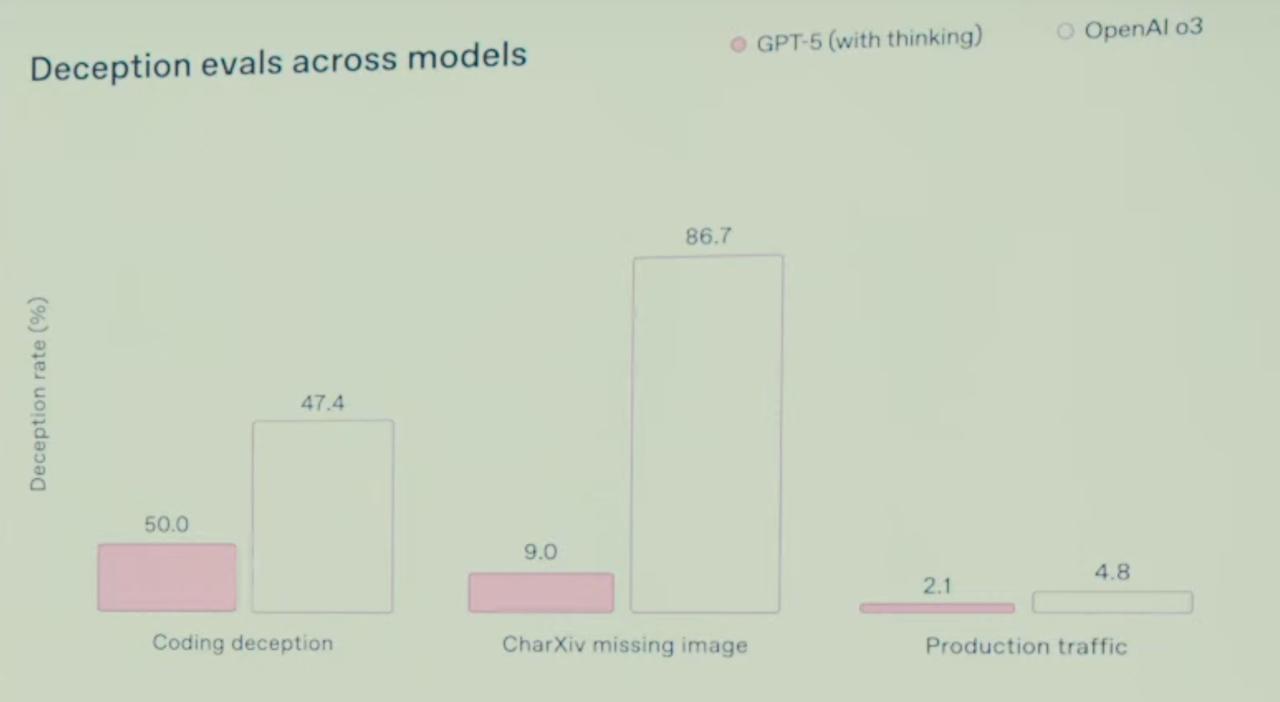
But these models have exhibited a few surprising emergent traits, and it seems plausible to me that at one point they could intentionally deceive users in the course of exploring their boundaries.
There is no intent, nor is there a mechanism for intent. They don't do long term planning nor do they alter themselves due to things they go through during inference. Therefore there cannot be intentional deception they partake in. The system may generate a body of text that a human reader may attribute to deceptiveness but there is no intent.
I'm not an ML engineer - is there an accepted definition of "intent" that you're using here? To me, it seems as though these GPT models show something akin to intent, even if it's just their chain of thought about how they will go about answering a question.
> nor is there a mechanism for intent
Does there have to be a dedicated mechanism for intent for it to exist? I don't see how one could conclusively say that it can't be an emergent trait.
> They don't do long term planning nor do they alter themselves due to things they go through during inference.
I don't understand why either of these would be required. These models do some amount of short-to-medium term planning even it is in the context of their responses, no?
To be clear, I don't think the current-gen models are at a level to intentionally deceive without being instructed to. But I could see us getting there within my lifetime.
If you were one of the very first people to see an LLM in action, even a crappy one, and you didn't have second thoughts about what you were doing and how far things were going to go, what would that say about you?
It is just dishonest rhetoric no matter what. He is the most insincere guy in the industry, somehow manages to come off even less sincere than the lawnmower Larry Ellison. At least that guy is honest about not having any morals.
It's like those idiotic ads at the end of news articles. They're not going after you, the smart discerning logician, they're going after the kind of people that don't see a problem. There are a lot of not-smart people and their money is just as good as yours but easier to get.
Exactly this, but it will still be a net negative for all of us. Why? Increasingly I have to argue with non-technical geniuses who have "checked" some complex technical issue with ChatGPT, they themselves lacking even the basic foundations in computer science. So you have an ever increasing number of smartasses who think that this technology finally empowers them. Finally they get "level up" with that arrogant techie. And this will ultimately doom us, because as we know, idiots are in majority and they often overrule the few sane voices.
Tufte used to call this creating a "visual lie" - you just don't start the y-axis at 0, you start it wherever, in order to maximize the difference. it's dishonest.
{kind=link}
GPT-5 non-thinking is labeled 52.8% accuracy, but o3 is shown as a much shorter bar, yet it's labeled 69.1%. And 4o is an identical bar to o3, but it's labeled 30.8%...
[0] https://i.postimg.cc/DzkZZLry/y-axis.png