I have used s5cmd in a professional setting and it works wonderfully. I have never attempted to test performance to confirm their claims, but as an out of the box client, it is (anecdotally) significantly faster than anything else I have tried.
My only headache was that I was invoking it from python, and it does not have bindings, so I had to write a custom wrapper to call out to it. I am not sure of the difficulty of adding native support for Python, but I assume its not worth the squeeze and just calling out to a subprocess will work for most user's needs.
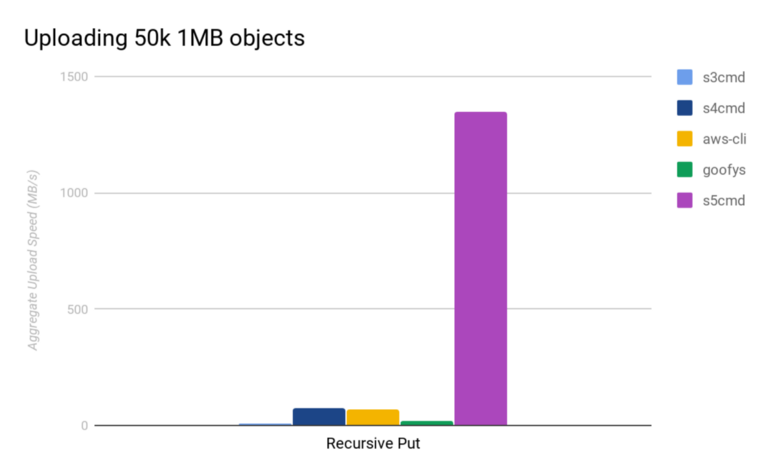
Very interesting. And this is an amazing graph for small file uploading/download speed improvement. I have the feeling that all cloud drives are really not optimised for many small files like smaller than 1Mbytes in average.
I've implemented at work once a rudimentary parallel uploading of many small files to S3 in Python and with boto3 (was not allowed to use a third party library or tool at that time) because it's soooo slow to upload many small files to S3. It really takes ages and even if you just upload 8 small files in parallel it makes a huge difference.
> For downloads, s5cmd can saturate a 40Gbps link (~4.3 GB/s)
I'm surprised by these claims. I have worked pretty intimately with S3 for almost 10 years now, developed high performance tools to retrieve data from it, as well as used dedicated third party tools for performant file download tailored for S3.
My experience is that individual S3 connections are capped over the board at ~80MB/s, and the throughput of 1 file is capped at 1.6GB/s (at least per ec2 instance). At least I have never managed myself nor seen any tool capable of going beyond that.
My understanding is then that this benchmark's claims of 4.3GB/s are across multiple files, but then it would be rather meaningless, as it's free concurrency basically.
I cant verify 40Gbps because I have never had access to a pipe that fast, but when I ran this tool on an AWS instance with a 20Gbps connection, it saturated that easily and maintained that speed for the duration of the transfer.
I just spawned a r6a.16xlarge with a 25gbps NIC, created a 10GB file which I uploaded to an S3 bucket in the same region, through a local S3 VPC endpoint.
Downloading that 10GB file to /dev/shm with s5cmd took 24s, all while spawning 20 or so threads which were all idling for IO.
Cranking up the worker count of the latter library until there is no more speedup, I can reach 6s with 80 workers. That is, 10/6 = 1.6GB/s, which seems to confirm my previous comment.
Okay I found the trick, buried in the benchmark setup of s5cmd.
The claimed numbers are _not_ reached with S3, but rather from a custom server emulating the S3 API, hosted on the client machine.
I think this is very misleading, since these benchmark numbers are not reachable in any real life scenario. It also shows that there is very little point in using s5cmd compared to other tools, since beyond 1.6GB/s the throttling will be from S3, not from the client, so any tool able to saturate 1.6GB/s will be enough.
The S3 API allows requests to read a byte range of the file (sorry , object). So you could have multiple connections each reading a different byte range. Then the ranges would need to be written to the target local file using a random access pattern.
You can spawn multiple connections to S3 to retrieve chunks of a file in parallel, but each of these connections is capped at 80MB/s, and the whole of these connections, while operating on a single file, to a single EC2 instance, is capped at 1.6GB/s.
It is definitely possible. Depends on how many 503s you might need to hit and when there heuristic model allows you to increase throughput. As a customer, you can also push for higher dedicated throughput.
I recently wrote a similar tool focused more on optimizing the case of exploring millions or billions of objects when you know a few aspects of the path: https://github.com/quodlibetor/s3glob
It supports glob patterns like so, and will do smart filtering at every stage possible: */2025-0[45]-*/user*/*/object.txt
I haven't done real benchmarks, but it's parallel enough to hit s3 parallel request limits/file system open file limits when downloading.*
{kind=link}
My only headache was that I was invoking it from python, and it does not have bindings, so I had to write a custom wrapper to call out to it. I am not sure of the difficulty of adding native support for Python, but I assume its not worth the squeeze and just calling out to a subprocess will work for most user's needs.