"This task can also be solved using iterative solution, but it’s way more complicated because we would have to nest for loops but don’t know how deep they are nested. The unknown number of nested loops is a common characteristic of all problems that are recursive in their nature and should give you a hint that recursive solution is required."
Would suggest instead something like
"We could solve this directly by managing our own stack of work done and keeping track of where we are in the problems as we divide them up, but it's easier to take advantage of the fact that the programming language is already providing us a call stack that can do this work for us."
Then, later, you can point out that this also helps with the backtracking solution as the programming language is maintaining the old environments; if you were iteratively managing your own stack you'd also have to backtrack manually.
Because that's how you transform a recursive call into an iterative one, not nested for loops. The general points made in the article still hold up, of course.
>Because that's how you transform a recursive call into an iterative one, not nested for loops.
I came to understand recursion through nested for-loops, though, but that might just be a historical accident. In the summer of 1988 I had written a Mastermind solver in Microsoft Quickbasic[1] for the specific case of 4 "pegs". At each guess, I used for-loops nested 4 deep to build a structure representing the possible remaining solutions (for all possibilities of the first peg, check all for the second peg, etc.) Then I wanted to extend it to work with variable numbers of pegs; after spending most of that summer trying to figure out a loop-based solution, I discovered that subroutines could call themselves and it hit me that I could have a function that took the possibilities already computed for a peg, and then called itself with those applied to the next peg.
So I've always thought of recursion as a way to have arbitrarily deeply nested loops.
[1] Believe it or not, it did support recursive functions!
But in reality recursion is an arbitrarily nested context that has nothing to do with loops per se (and that's why sometimes it requires the stack and sometimes it does not).
Honestly, I think your version is less clear on its own in that it obscures the main point of that particular statement: when it's best to consider recursion instead of nested loops.
In other words, the original is a statement about why or when to use recursion, while yours is a statement about how recursion helps.
I'm open to rewording, but my core complaint is that the text is factually incorrect; the way you iterative-a-tize a recursive algorithm is not with nested for loops. I wouldn't even say it's good didactically; it reinforces the very wrong ideas that we're trying to sweep away at exactly the wrong time.
I think it's also helpful to explicitly see recursion as using the fact that our programming language happens to have a stack lying around to do stack things, instead of implementing our own stack. It also tends to at least bring the things AstralStorm is discussing to mind, when you think about it that way, namely, that you have to consider the limitations of your local call stack before you go too crazy with this stuff. Recursion algorithms that involve more than O(log n)-deep calls must be eyed very carefully. And O(n) certainly comes up a lot; best avoided if you don't have a tail-recursion-optimizing language.
>the way you iterative-a-tize a recursive algorithm is not with nested for loops.
>it reinforces the very wrong ideas that we're trying to sweep away at exactly the wrong time.
I think I'm missing something. Recursion, by definition, is iterative--at least in terms of it involving the repetitive application of some operation(s). Maybe I'm misinterpreting something, but I've most heavily used it in backtracking and decomposition problems which otherwise couldn't be solved as elegantly. So, my experience has not been so much one of "iterative-a-tizing" a recursive algorithm, but "recursive-a-tizing" an iterative one.
What applications/ideas are we trying to sweep away?
>I think it's also helpful to explicitly see recursion as using the fact that our programming language happens to have a stack lying around to do stack things
Completely agree with this and the larger concept of understanding how idioms you're using actually work under the hood. Some languages make certain constructs easily accessible and very easy to misuse (e.g. ThreadLocals). The simplicity of their interfaces belies the massive trouble that can easily be created, absent an understanding of their implementations.
"I think I'm missing something. Recursion, by definition, is iterative--at least in terms of it involving the repetitive application of some operation(s)."
In this context, "recursive" means "decomposing the problem with function calls", as the post is discussing, and "iterative" is a sloppy-catch all term for "doing things with for loops and such". It's sloppy because you can't just say "doing things without calling functions" because there are of course non-"recursive" ways of calling functions in an "iterative" routine (for a simple example, calling a logging function).
Please pardon the sloppy terminology here; since we're discussing beginner concepts here it's hard to avoid. (For instance, most beginning recursion discussions focus on a function that calls itself, but you can have recursion where A calls B which calls A etc., or more complicated routines for things like traversing a parse tree, where the function called depends on node type; I've witnessed a student claim that those can't be recursive because recursive functions are only recursive when they call themselves.)
That's a technically precise definition that has a boolean-precise meaning, but it doesn't correspond terribly well to what people generally "mean" by the term. Eventually programs people think of as "iterative" will end up with cycles in the call graph simply due to sheer size, rather than the use of any recursive techniques.
You'll probably find that if you try to create a precise definition of what people generally mean, you can't. Since that's my belief, I didn't try very hard. Getting too wrapped up in labels is often an impediment to understanding anyhow; what's important is that there are legitimately two distinct ways of thinking about how to code, and we aren't really that well served by insisting that they can't be labeled because they can't be precisely defined. (Well, more ways than that, of course, but we're discussing two today.)
I want to agree that languages are squishy and hard to define things. Some things are well known, but undefinable. I have yet to read a satisfactory definition of "cookie", I mean the little (except when they are big) baked good (except when they aren't baked) that are generally round (except when they aren't) and not the things web browsers store. Most definitions leave out one or more things on common grocery store shelves.
I disagree that we can't strive for precision in technical discourse. Programming languages have precise meaning and are executed precisely by a machine. As an industry we are still working to define what these machine can really do to help along precise definitions can aid in communication complex topics. We could not have loops or recursion if simpler construct like conditions, jumps, gotos, variables and others did not have precise definitions.
It does seem that this, how humans approach problems with these two kinds of problem decomposition, is close to the boundary of natural and machine language. This might rule it out from precise definition, but it seems to be worth a try to me.
I think iteration and recursion can be defined perfectly well.
If people unconsciously create a more complex cycle, that might even be decomposable into distict smaller cycles, then thats still a perfectly fine recursion.
A program can apply both, recursion and iteration, together to solve a problem. Maybe the problem in the conversation is that it's context is implicit and inconsistent.
A recursive solution can always be written as an iterative one. Recursion is just a treat given by the language. There could be a language where any type of recursion on the language-function level is forbidden, but I doubt it would be terribly successful.
Indeed. That is a concise definition of recursion. But why have a cycle in a call stack (implicitly linearizing a graph) when you can replace it with a cycle in your data structure without spooky action at a distance controlled by a compiler?
In an explicit representation of the "work graph" you can easily prove a finite number of walks or a cycle (and then break it in some way). Doing that directly for a nontrivial function without using graph theorems is much harder.
Yes it is "easier" syntactically but then also easy to shoot yourself in the foot. Since a function call is a primitive you only get primitive tools to handle problems with it. Exceptions for example tend to unwind the stack which can take a long time. In functional languages you can end up with Bottom state from nowhere or a plain old crash.
Simple answer: never unless you happen to have unbounded call stack depth.
Stack sizes are limited on all architectures I'm aware of, on some even drastically. And stack overflows are very tricky to handle correctly.
Unless you want to limit recursion depth manually or have proven that overflow cannot happen with a formal proof. (With your bounded stack size.)
In all other cases, explicit data structure (not necessarily a stack) will both make debugging easier and additionally uncover performance problems you haven't thought about.
Well, I wasn't offering an opinion as to when recursion should be used--merely pointing out that the GP's proposed change didn't hold the same meaning as the original.
>never unless you happen to have unbounded call stack depth.
But, since you mention it, I'd have to disagree with your assertion. It's not just about call stack-depth or artificial limitations. There are plenty of use-cases wherein the search-space-depth itself is naturally bound, but unknown/variable down any particular path (e.g. category hierarchies). And, yes, we can impose reasonable "manual" limitations on still more use-cases to expand this universe even further.
Using recursion in these cases is far more elegant than nested loops.
All physical machines have limited memory and therefore limited stack and heap sizes. Getting a stackoverflow or running out of memory are the same thing. So going from the stack to the heap doesn't mean you don't have to formally verify it.
I think this would be a better lead in than jumping straight to explaining where recursion is useful. Personally, I found it much easier to understand recursion once I had spent enough time experimenting with recursive functions to understand how to convert any algorithm between loop structures and recursive functions.
Trying to understand why I'd want to use one over the other followed from that.
The problem is most introductions to recursion teach the syntax and implementation, not the conceptual structure.
The syntax is (usually) "a function calls itself, and there's a stack which can cause problems, except in some languages, probably."
The conceptual structure is "Solve a complicated problem by finding a single algo that successfully attacks the problem repeatedly, making the unsolved/unprocessed part smaller and smaller. Repeat until there is no unsolved/unprocessed part left."
Then illustrate with examples like Hanoi that demonstrate how simple logic applied over and over solves a complex puzzle.
Of course it's easy to introduce recursion with factorials, but factorials (etc) don't really explain why recursion is powerful.
They make it look like "Work out this simple math problem (which would be even easier with a for-loop, but whatever) with this one neat trick."
> it's easier to take advantage of the fact that the programming language is already providing us a call stack
Exactly, I think this point is often overlooked, because folks get stuck thinking about the syntax of what they're writing rather than how it works under the hood.
It's nice unless your language has a limiting call stack. JVM languages are notorious for this. You can increase the size of course, if you have the right amount of machinery. Else it's time to explore tail call recursion and other "anti-unrolling" strategies.
I think a useful litmus test is to consider the worst-case depth of whatever you're building. I often feel safer writing my own userland stack, even for stuff like DFS in an interview.
You can't always know how much of the implementation stack will already be used by whatever calls your code, after all. It's a weird kind of "shared resource".
This neatly explains why recursive depth-first searches are far easier to implement than recursive breadth-first searches. With BFS you'll need to explicitly pass in a queue to track unvisited nodes, whereas with DFS you already get a stack for free!
Recursion shouldn't be difficult, but we write recursive programs using one tool: self-referential functions. That's like trying to write structured programs using one tool - goto.
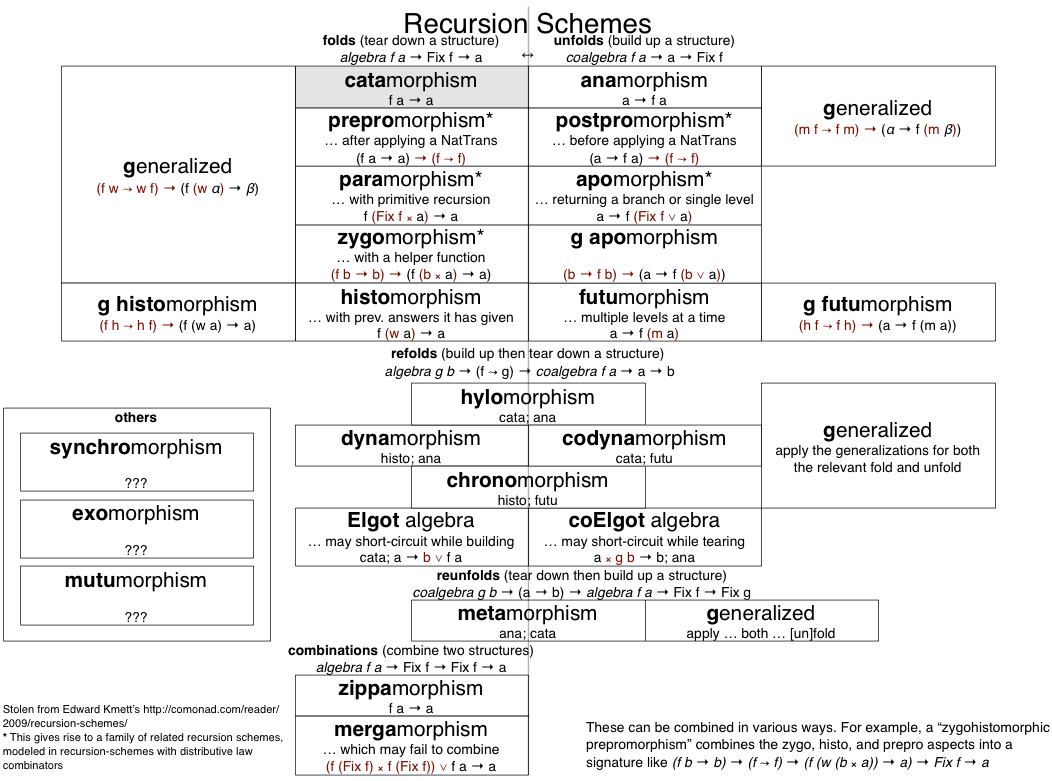
Functional Programming with Bananas, Lenses,
Envelopes and Barbed Wire[1] pioneered generalized recursion schemes and influenced work in Haskell[2] and Scala[3]. It's great having the vocabulary to describe recursion and the tools to elegantly recurse, but anamorphism tends to shut down conversations faster than mentioning the m-word.
> It's great having the vocabulary to describe recursion and the tools to elegantly recurse, but anamorphism tends to shut down conversations faster than mentioning the m-word.
Consider nudging the library authors to write a few words first [1]
To me it seems like it might be a kind of "silver bullet" for programming, due to a number of factors: simplicity and elegance, suitability for partial evaluation and super-compilation, and for parallelization.
I haven't tried to implement a large system in it yet though. If I get the time I hope to re-implement the Oberon OS using Joy.
Catamorphism, anamorphism, hylopmorphism, as opposed to something like fold/unfold, foldAndUnfold. There are of course, many more[1]. Meijer et al just chose a goofy name for their paper.
This is a recursive structure since a Tree can be made up of other Tree's. We can take a slice of the tree:
data TreeNode a child = Branch child child | Leaf a
data Fix f = F (f (Fix f))
type Tree a = Fix (TreeNode a)
sumTree :: Tree Int -> Int
sumTree = cata algebra
where
algebra (Branch a b) = a + b
algebra (Leaf a) = a
You might notice that we didn't do any recursion in sumTree because cata captures how to traverse the tree. Catamorphisms are the simplest recursion schemes, there are variants that keep track to our position in relation to the rest of the tree or memoize computations and so on.
I agree a lot with the first point. Writing recursion algo using C/C++ or any other imperative language I've tried is like crawling through minefield, from one StackOverflow to another. I found that's because we've learned to write imperative programs from the entry problem to support all the cases.
I've changed my mind about recursion after I've learned to start writing the recursive algos backwards - starting from the ending condition and then moving to add support for basic recursion and adding real entry point at the end. That way instead of waiting for next segfault you try and implement each important step, one at a time. I've learned this thanks to how Erlang makes you write recursion (from "Learn you some Erlang" book).
In C design and problem/solution recognition is everything. That takes years of experimentation and working through test cases. Otherwise you can assign C to the minefield category and you will jump on another bandwagon.
My dream team composition is 3 15 year C programmers and a core lisper.
I didn't completely grok the white paper you linked. Is it basically suggesting that we remove the capability for arbitrary recursion and limit it to a set of recursive primitives (folds, filters, zips, etc)? And the motivation for this is comes from the idea that arbitrary recursion is as dangerous as go tos?
The big contribution of the paper is providing a vocabulary for describing generalized recursive patterns. The vocabulary Meijer et al chose (un)fortunately didn't stick; we now know these operators as catamorphism = fold/reduce, anamorphism = generators, hylomorphism = streams.
There's a fair bit of unexplored territory surrounding these operators, with some intriguing possibilities. For one, replacing arbitrary recursion with ana/cata/hylomorphisms lets you prove termination (or at least forward progress) of a fairly large subset of programs, including servers, GUIs, and event-driven programs! See eg. the research on total functional programming for this.
Also, folds and unfolds generalize to any algebraic data type, not just lists. Basically, a fold on lists means replacing the Nil constructor with a value and the Cons constructor with a binary operation. The same analogy holds for any ADT: given a sum-of-products types with N alternatives, the fold function for it is an N-argument function where each argument is a function from that alternative to the new accumulator value. This opens up the possibility of auto-generating fold functions from data type declarations, meaning the programmer would never have to write a loop or recursive function again, only specify the transformation at each stage of the recursion.
So, in other words, a language needs general recursion in order for library authors to implement map/fold/reduce etc. However, everyday programmers shouldn’t use general recursion, but rather stick to these library constructs (for the sake of correctness)?
By that definition a while loop is general recursion. Neither map, fold nor reduce require recursion to implement. All are either for or while loops and this is how the actual computer is going to execute them. Our Von Neumann machines execute lists of instructions and not functions. They are inherently stateful.
If-statements and all loops are all some form of "jump if zero/not zero" at the assembly level - so you could (and under the hood have to) implement all control structures used in higher level languages with conditional gotos, and probably even come up with a few more exotic control structures that might be better in rare situations.
But despite that flexibility we prefer to use the abstractions we're familiar with, as it makes it much easier to reason about the code (when you're using when you read a for loop or an if statement you know what it does, you don't have to spend extra time figuring out what a particular conditional goto construction does).
The idea is that plain recursion is like goto: a fundamental building block to the implementation, but not the abstraction level you want to work with if you can avoid it.
This article touches on some good points. In particular, the part about trusting that the function will do the right thing is something that people who already understand recursion take for granted but is extremely crucial. However:
"Let's tweak our sum function a a bit: ... That's it."
I really dislike articles that earnestly try to convince the audience that some subject which many find extremely difficult to understand is actually very simple. My impression is that the intent is to help people who lack the confidence to engage with the topic, but in my opinion the exact opposite effect is achieved. At that point in the article, nothing about recursion had been explained and it's not reasonable to expect someone who previously did not understand recursion to read that section and come to the conclusion "that's it!" Instead they'll be sitting there, extremely confused by something which they're being reassured is actually quite simple. This is not going to help their confidence.
So while I appreciate the author's intent, I think that someone who is struggling to understand recursion might leave this article worse off than when they started. And I wish this trope would disappear from tutorials.
I auto-ignore tutorials that say stuff like, "X made simple". It's almost always trying too hard to make a genuinely difficult subject easy, thereby obfuscating the topic more.
I learned long ago that books titled like "advanced X" will be a very simple book on X suitable for any layperson with basic knowledge. Books titled "introduction to X" or "elementary X" will be extremely difficult.
I have not yet seen books titled "advanced X" that are actually grokkable, but my university courses called "introductory X" were exactly the hardest ones.
In general, laying foundations to any broad topic is hard! I imagine knowledge to be like pyramids, where the bottom support the top. But to support a tall pyramid, a large bottom is required. Thus, we get these obscenely difficult 'intro' books...
Try going to a "technical college" instead of a university. All your text books will be "advanced X". These schools have earned their reputation for being easy to pass.
I remember in college that I took some examples of recursive functions, hand-wrote the call stacks, and spent hours and hours pacing in a study room, thinking about it, until the patterns started to feel natural.
I did that kind of thing more than once, just working through algorithms in my head, I guess learning to trust that it'll work, as long as there's a path from the allowed arguments down to the base case. For me, it was never something that reading a few words could clarify.
I agree with your sentiments about this style of article, but I’d say recursion is simple—the problem is that “simple” doesn’t mean “easy”. A lot of programming & math concepts were like this for me when I was first exposed to them—amazingly simple and clearly useful after they “clicked”, frustrating and inscrutable before.
I was thinking of things like monads. They’re a class of type constructors with a couple of associated functions (unit & bind or unit & join). The definition is undoubtedly simple, as well as fundamental in Haskell. But understanding how to use them, what to use them for, how to tell whether & why a type admits monad/applicative/functor instances, &c., are still difficult things for a lot of people, because these are unfamiliar abstractions. Moreover, they take advantage of unfamiliar features like higher-kinded types, so you can’t even explain them by offering a translation to other languages, because most other languages lack the ability to adequately express them.
For myself, I think of learning as “discovering simplicity”. I know I understand something when it finally feels as simple as it really is.
I find claims that something is simple are often just misleading. It's really common to see these kind of claims with articles talking about learning a foreign language. Often the grammatical rules and concepts ARE quite simple. But you often find sentences where several simple rules are piled on top of each other and you end up with something that takes some time to understand.
For example, in German there are straightforward ways you modify the definite article associated with a noun based on whether it is the subject or object in a sentence. A fairly simple, and useful concept! But first you have to remember what gender that noun is, which is fairly challenging in german because there are several word endings for each gender. Next you might need to pay attention to how the sentence has been constructed: in a relative clause, the definite article after the comma is associated with the noun BEFORE the comma - and that definite article is different because it is in a relative clause!
Yeah, looks like the author is not doing a good job at explaining recursion. If I had to do it I would probably visualize stack and show how function calls work.
I agree, this kind of "it's all so simple" approach is often less helpful than folks think it is.
I always try to explain it thusly: Recursion makes big, complicated problems easier to solve. But it's a bit like using a cannon to swat a fly if you have no big, complicated problems to wrestle.
Explanations like this do not deny the complexity present in the scene, but reframe it so that were using a technique to tackle said complexity.
Agreed. This is just like when I tried to grok monads. So many articles trying to tell me how simple they are... yet still so many articles needed to explain it (and I'm none the wiser)
You don't really understand how difficult recursion is until you've tried to teach a bunch of programming newcomers the concept. A few get it quickly, but for the rest all the "think of it like ..." suggestions don't really help. It's a concept that everyone seems to have to learn through practice (as the author implies). I fell into the trap that if I only explained it clearly enough I could make it easy for others. Everyone learns it their own way and you just have to give students enough opportunities to practice for them to get it. I don't disagree with Dijkstra that the concept shouldn't be difficult, but I do not believe there are any easy paths to the concept for most.
It's one of the most interesting learning processes in that once you get it, it feels almost as simple as a for loop or simple math. But until you get it it feels like the most opaque, impenetrable wall where 1+1 != 2.
Side note, recursion would be slightly easier if the concept of a base case were applied to all functions as preconditions. The idea of a base case really has more applicability than just in recursion, it's just that we don't call it a base case in other situations.
Recursion is also interesting to implement when doing TDD. It comes in a refactoring step, of course, but you don't have to think about the base case(s) because they've already been done. Again, not suggesting this is helpful to a newcomer struggling, but is just an interesting process.
Side note, recursion would be slightly easier if the concept of a base case were applied to all functions as preconditions. The idea of a base case really has more applicability than just in recursion, it's just that we don't call it a base case in other situations.
Function heads in ML and Erlang make this explicit when used correctly, and I agree.
> I'm having a hard time figuring out a base case for say calling toString on an object, or incrementing an integer.
In both cases, we can special-case the "zero" of the domain. For example, toString of an object without any attributes would return '{}', while incrementing the integer zero would return 1.
I'm not sure about the usability of the latter in an iterative approach, but the former could definitely be used as the basis of an iterative algorithm that traverses all of an object's attributes.
No because that comment was poorly worded and overbroad.
I'll narrow it to say that drawing a parallel between base cases and preconditions might be helpful when dealing with functions / methods that are more complex than lambdas or their equivalents.
Thanks, I should have thought through that part more carefully before posting.
> This is because a recursive sub-function never solves the exact same problem as the original function, but always a simpler version of an original problem.
This isn't always true. There are plenty of recursive functions whose purpose is merely to climb until a condition is met that there are no more rungs in the ladder.
Recursion is difficult because it isn't just taught, it is mythologized as the potentially infinite source of a one's love for programming. If teachers similarly mythologized the "switch" statement I'm sure they could confuse the topic of conditionals just as easily.
>> This is because a recursive sub-function never solves the exact same problem as the original function, but always a simpler version of an original problem.
> This isn't always true. There are plenty of recursive functions whose purpose is merely to climb until a condition is met that there are no more rungs in the ladder.
What do you mean here? What is the ladder in your analogy? The stack? Is the "a condition" that the stack has reached its limit or that you have reached a base case?
If computing f(50) requires computing f(50), it will never end. Likewise if you have a base case at 0, if f(50) requires computing f(51), it will never end. You must solve a problem closer to your base case than the original problem.
> Recursion is difficult because it isn't just taught, it is mythologized as the potentially infinite source of a one's love for programming. If teachers similarly mythologized the "switch" statement I'm sure they could confuse the topic of conditionals just as easily.
I don't think that recursion is mythologized. It allows you to express the core idea of the algorithm really succinctly.
For example defining the Fibonacci sequence just requires the beginning numbers and the rule for progression.
fib(n):
if n = 0 or 1: return 1
return fib(n-1)+fib(n-2)
It is much simpler than the iterative solution (though generally being inefficient).
Often the simplicity gained by using recursion (if you are comfortable with it) makes it possible to understand algorithms you could not understand the iterative form of.
Also, recursion is simply more powerful than just while or for loops (you need stacks as well). And when you add stacks into the mix, iterative programming can get very confusing.
Simpler than the iterative is hard to argue -- it's closer to a strict mathematical definition but the iterative version can also be setup very simply too.
To say one is more powerful is really false. I think recursion is great, and for some situations it should be the go to method, but anything you can write iteratively you can write recursively and vice-versa.
> To say one is more powerful is really false. I think recursion is great, and for some situations it should be the go to method, but anything you can write iteratively you can write recursively and vice-versa.
I mean powerful in a strict theoretical sense. Without using a way to freely allocate arbitrary memory, recursion can compute things loops cannot. The ackerman-peter function is an example.
Loops however can be trivially converted into functions.
Therefore because loops can be converted into recursive calls and recursive calls cannot always be converted into loops. Recursion is more powerful.
Practice makes perfect, I think most learners can get comfortable with recursion as they use it to implement simple recursive solutions (Fibonacci, tree traversals..etc). Over time it becomes quite natural to recognize when and how to use recursion.
One source of confusion that most learners have stems from the seemingly mysterious way that intermediate results are kept track of. This is one of the downsides of not having experience with low-level programming. If you're familiar with assembly language programming and understand how register contents are pushed/poped on/off the stack between sub-routine calls then it is easier to understand what is happening behind the scenes.
> If you're familiar with assembly language programming and understand how register contents are pushed/poped on/off the stack between sub-routine calls then it is easier to understand what is happening behind the scenes.
Assembly programming in college is exactly what made recursion really click for me!
I taught myself to be comfortable writing recursion through practice, practice, and practice, but I feel like things clicked at an entirely different level when I could trace something in assembly and see that the arguments were actually being stored in different locations as the stack pointer increased.
Of course, Fibonacci is kind of an awful example, since the naive recursive solution is O(n^2) and besides it's much easier to implement iteratively. It's a decent toy problem, but it makes me worry that it gives people the wrong idea.
Or writing a recursive decent parser. Anyone learning recursion needs to write a simple recursive decent parser (say, for evaluating math expressions).
Anything that is self-referential is hard. I remember when we covered proof-by-induction in HS math. There was a significant fraction of the class that did not believe a given proof was sufficient.
If you can't assure yourself of the correctness of a fairly simple recursive function that is given to you, then composing one yourself is going to be nigh impossible.
[edit]
From the article: Instead trust that it returns correct sum for all elements of an array a[i]
This is exactly the point where many people get hung up. They cannot proceed to reading the next line until they understand how the recursive call works. They are unwilling to trust that the function works as advertised, and cannot shift gears to continue past that. In my experience, telling them to "just trust it" and such seems to not help much.
> In my experience, telling them to "just trust it" and such seems to not help much.
Just call that recursive function something else. Give it some other name, and say that we must take it for granted that this other name is a function which is already debugged and tested by another team of programmers:
Here, we rely on member, a standard function in the language already, and so there is no recursion.
We first convince ourselves that what we have works.
And then, final step: since what we have works, it means that our-member is a correct implementation of member, which means that the two are equivalent. Equivalent functions are substitutable. And so we can just perform that substitution: replace the member call with our-member.
By the way, it occurs to me that Hofstadter's Gödel, Escher and Bach might be a good source of ideas on how to deal with presenting and teaching self-referential topics.
Give it some other name, and say that we must take it for granted that this other name is a function which is already debugged and tested by another team of programmers
That seems like it's "begging the question" --- as in, "if there's already a function written to do what I want, why do I need it to write one to do it...?"
But that problem is present in virtually all homework in CS.
Someone already wrote a Celsius to Fahrenheit conversion function, a simple ray-tracer, a quicksort, a toy Lisp, a text-file-based simple inventory system, etc ...
We could make up a back story about this to give it real-world plausibility: yes, the function is already written, but it's in an expensive, proprietary third-party library which we cannot ship without paying royalty fees and being bogged down with various inconvenient restrictions.
Now everyone in the class should quickly agree that this function works. Next say "our goal is to write our own implementation of member, so we will handle one special case at a time until we don't need to call member anymore"
so step 1:
(defun our-member (item list)
(cond
((atom list) nil) ;; if it's not a non-empty list, it can't be a list containing item
(t (member item (cdr list)))))
step 2:
(defun our-member (item list)
(cond
((atom list) nil) ;; if it's not a non-empty list, it can't be a list containing item
((eql (car list) item) list) ;; if the first element of the list is our item,
;; we have a match and return the whole list
(t (member item list))))
step 3:
(defun our-member (item list)
(cond
((atom list) nil) ;; if it's not a non-empty list, it can't be a list containing item
((eql (car list) item) list) ;; if the first element of the list is our item,
;; we have a match and return the whole list
(t (member item (cdr list))))) ;; we already know that the first item is not a match, so we can just run
;; member on the tail of the list
And now demonstrate that replacing member with our-member will still be correct.
It's often easier to accept this definition, because trusting that the built-in will work is comparatively simple. You then ask the audience what would happen if you replaced the call to the built-in with a recursive call.
Edit: It appears I've written an identical comment to my sibling.
This is exactly the point where many people get hung up. They cannot proceed to reading the next line until they understand how the recursive call works.
...which is why you should always teach recursion by starting with the base case and build on it with a recursive call, not the other way around. Step through an example execution of the algorithm with no recursive calls --- only the base case. Then step through with one or two levels of recursive calls, and they'll usually start seeing the pattern of how it works (and be able to generalise to n levels.)
Iteration is also self-referential. New iterations refer to prior values, and jump backwards to prior code.
I think the way to teach recursion to programmers who have mastered iteration is to teach the tricks for transforming loops into tail recursion: start by equating the self reference with the establishment of new values for the loop variables and the backward branch.
We identify the loop variables: a, b, n, and acc. First, we can rewrite this using a form of "goto with parameters".
#define dot_rec(label, na, nb, nn, nacc) { \
/* capture argument evaluations into fresh temporary variables */ \
double *tna = (na), *tnb = (nb); \
size_t tnn = (nn); \
double tnacc = (nacc); \
/* store temporaries to loop variables, and jump backward */ \
a = tna; b = tnb; n = tnn; acc = tnacc; \
goto label; \
}
double dot(double *a, double *b, size_t n)
{
double acc = 0.0;
again:
if (n != 0) /* we can now use (n > 0) since n isn't decremented! */
dot_rec(again, a + 1, b + 1, n - 1, acc + *a * *b);
return acc;
}
Thus if n is not zero, we update a with a + 1, b with b + 1, n with n - 1, and the accumulator by adding a + b.
The dot_rec macro ensures that the expression * a is not affected by a receiving a + 1; it mimics the binding of argument expression values to fresh arguments.
From that we can go to recursion:
double dot_rec(double *a, double *b, size_t n, double acc)
{
if (n > 0)
return dot_rec(again, a + 1, b + 1, n - 1, acc + *a * *b);
return acc;
}
double dot(double *a, double *b, size_t n)
{
return dot_rec(a, b, n, 0.0);
}
Get people comfortable with mechanically converting iteration to recursion, even in cases where recursion isn't all that nice, and requires additional parameters and possibly the splitting of a function API into a non-recursive and recursive part.
Then go into non-tail recursion; recursion in which the parent actually does something with the return value other than just return it: those true divide-and-conquer problems.
Then mutual recursion among two or more functions, starting with something trivial like odd(n) and even(n) that mutually tail recurse.
When I was a kid, we learned the principle of mathematical induction in algebra class. That made recursion seem easy.
As for the limitations of recursion on any given system, that's easy to learn because... kids will be kids. Practically the first thing I tried with recursion, ended up with the system operator yelling at me, and learning what a core dump looked like.
If you want to really delve into recursion, I recommend to learn a logic programming language like Prolog.
Interestingly, Prolog programs are often efficient and general because, due to the power of unification, Prolog programs are more often tail recursive than functional programs.
For example, we can define a relation called "append" in Prolog as follows:
In Prolog, recursion naturally arises by considering the inductive definitions of terms. For example, you can read the second clause as "If it is the case that append(As, Ls, Rest) holds, then it is also the case that append([A|As], Ls, [A|Rest]) holds".
Note that such cases are not naturally tail recursive in Lisp, for example, because in languages that do not support unification of logical variables, there is one additional call of "cons" after the recursive call to construct the result. Also, the Prolog version is much more general and can be used in several directions! For this reason, "append" is not even a good name for such a relation, because it already implies one particular direction.
The two biggest problems with recursion in practical use is that not all compilers can properly handle optimizations around tail calls, and not all TCO capable compilers can handle all tail call cases.
If either case occurs, you run into the issue where you will seemingly randomly blow out your stack space when your list is too long, or your tree too deep. Then you have to fall back to a non-functional idiom (or do some other magical incantations to avoid function stacks, like Clojure's `loop` special form).
I think recursion is a great tool, but it's so poorly implemented in so many languages that it's simply too dangerous to use.
If recursion could be tail-optimized, it's usually better just to write iterative `white`, unless you can't use mutable variables. The interesting recursion which can't be trivially replaced with loop is not tail optimizable.
You can implement state machines as a set of mutually-recursive functions with one state = one function. Works very well, is tail-recursive and not trivially replaced by loops.
It is quite replaceable if you represent the actual graph as a data structure with terminator nodes. No need for more recursion - the data structure is recursive, but algorithm is not.
It is even easier to prove bounds. You get to prove correctness for cycles (if applicable), connectedness of the graph and whether a terminator node is connected to all acyclic arcs. (Latter can be a trivial proof on the constructor.) Just like for recursive implementation except proving the cycle lemmas is easier.
In clojure you can always write a macro that will define your recursive function in an implicit loop form, if writing "loop" looks bad.
That (or plainly using loop) forces you to be explicit whenever you want to use tail recursion (still unsure whether this is good or bad). But the good news is that now the compiler will catch as an error whenever you intended to use tail recursion and your function wasn't tail-recursive, which I'm sure has caused more than a headache in other recursion-heavy languages.
2) college C course: imperative "print tree", easy
3) advanced compiler: more sophisticated environment thingies, clueless again
4) CGI quadtrees: want fully recursive solution but chokes
5) rediscovery of lisp: recursion wannabe
6) cons-based lists fundamentals: linear converging recursion is everywhere, pattern is easily understood and memorize, everything makes sense
7) FP and lispy combinatorics (treerec, partition, countdown): it seems like point 2) but something is different now.. deep recursion involves self closing types. It's not just repeat until and do not care about what happens you'll fix it down the road. It HAS to make sense, and to typecheck right away.. recursive steps will be used for the previous level it has to fit logically.
If one reaches that level your understanding shifts entirely. Recursion is it's own solution, it's absurd but it's a deep reference point to solve problems since you can assume something that doesn't exist and see if it holds..
Now you get to rediscover math proofs and a lot of late HS and college math. Finally something I wanted to know and recently found out about, list recursion are only a linear pattern of recurrence. It's one dimensional and often on an easy to proove converging variable (cdr + nil?, natural dec + zero?). There are n-dimensional patterns, and litterature about it. I can't recall the books but I'll dig for it.
And finally, Turing among other tried to rethink imperative programs as one big while modifying one big vector variable (aka system state) and proof that this n-dimensional vector could only have some sound values and would reach terminating ones. (I think it's called linear ranking ..)
You mean a deterministic state machine? Sheer number of states makes the approach less than useful.
Tree recursion is often also easy to prove. Kd-tree operations (incl. quadtree) are tree recursion. The only problem with it may be cache locality.
The only trouble is you have to prove you're walking the tree in one direction for correctness. To prove that in a row system rewrites some pretty interesting monads.
It greets even trickier once the recursion tree is uneven or lopsided, like in R-trees. Then you get to think about upper bounds etc.
Some years ago I had problems with recursions too, because I always had some edge cases which made my functions go wild (endless loops). But one day someone told me, that most recursive programs can be written into the skeleton below:
function a(){
if(/* Termination Condition */){
return /* Special Element */
} else {
/* Recursion: e.g. a + a */
return a() + a()
}
}
It is very rare that the tail-recursive form of a function is more readable than the non-tail recursive form. I find tail-recursion intellectually interesting, but of little use for actual programming.
Contrasted with tree-recursion where the code is often so pithy that its correctness is obvious (assuming you understand recursion).
Tail recursion sometimes comes up naturally. It's essentially a goto with parameters. Thus it comes up where goto is also (at least borderline) useful, eg implementing state machines.
This structure doesn't prevent tail-call recursion. It's a good template for most instances of recursion. To modify the GP's version, you'd just need to add an accumulator parameter to the function (or to some higher scope, global or class) which could be modified and tested on each recursive call.
Technically you can convert to a tail-call form (such as CPS) but regardless, you can't get away with consuming O(d) space where d is the depth of the tree.
Not necessarily. The form the OP posted is fine for most recursive calls and won't consume large amounts of memory unless the iterative equivalent would as well if you put it in tail call form:
function f(n,acc) {
if(n == 0) return acc;
else return f(n-1,acc*n);
}
function fact(n) {
return f(n,acc);
}
That's exactly the structure the OP suggested and in this case won't use O(d) space if tail-call elimination is available in the language. Now, if the accumulator is growing a list result like map or some tree traversal, sure. It'll use O(d) memory. But so will the iterative equivalent.
Well, if you're hung up on the OP's code, they do the same thing twice so we could maybe just double the result when we put it into the accumulator.
If you read what I wrote I've qualified my statements properly. Not everything in the OP's form will be able to be made tail recursive. But the form they presented does not bar tail recursion and efficienct tail recursion at that.
Anything that can't be made efficient recursively would likely also use gobs of memory and time if constructed iteratively.
I admit this is complete speculation on my part, but I can't imagine it helps to combine recursion with C-style for-loops.
Both pieces of advice from the article: "trust the recursive function" and "don't try and trace the execution" seem easier if the control flow is simpler.
Compare:
function sum(a) {
let result = 0;
for (let i = 0; i < a.length; i++) {
if (Array.isArray(a[i])) {
result += sum(a[i])
} else {
result += a[i];
}
}
return result;
}
function findCeo(employee) {
let boss = employee.getBoss();
if (null == boss) {
return findCeo(boss);
}
else {
return employee;
}
}
I have a problem with the second example. An attribute to track the title of an employee would solve the problem of finding the CEO and any other type of employee, this should not be done with recursion. If recursion is such an important concept we should have real-life examples of it being employed properly to lean on.
Also am I missing something or does your findCeo function return the employee when they have a boss and recurse when they have no boss? Seems like this just returns the employee in most cases and infinitely recurses for the CEO who presumably has no boss.
An attribute will only work if you are given a list of employees or other iterable structure.
My real example is that in my day job different business units of our customers are represented by a hierarchy, and you frequently traverse that hierarchy looking for some feature that's derived from the ancestor.
But really this is any algorithm that looks up a tree.
The first problem in the OP is ill-typed, so if this was intended to help people get a good grasp on recursion, that may be counterproductive.
I never had any problem using recursion, but my ability to reason about it at an abstract level is due in large part to the excellent paper "Functional Programming with Bananas, Lenses, Envelopes and Barbed Wire", which covers various abstract approaches to dealing with recursion schemes. https://maartenfokkinga.github.io/utwente/mmf91m.pdf
I think part of this can be explained by the way recursion is handled on major platforms. Even something like Python which has some functional leanings is prone to stack overflows with deep-ish recursion without hacky workarounds. Once the tools most people are using are more recursion friendly, I think we'll see it become more mainstream. I think JS has TCO now, at least on Node, which is a huge step in that direction.
Unless I'm reading that wrong, TCO was pulled as even invokable by a harmony flag because it was so broken to be a security risk.
I wonder if there are any explanations other than focus or priorities as to why it appears to be harder to implement in Chrome than it was in Safari/webkit.
Anyway, since it's not in V8 that means it's not in node right?
To understand recursion get "The Little Lisper" or the later book "The Little Schemer". To know when not to use recursion and use iteration instead, look at "Algorithms + Data Structures = Programs" and finally, you can delve into the mathematics of primitive and non-primitive recursive function with "Recursive Functions in Computer Theory".
For one it's not handled well by many languages, expensive stack cost, not tail call optimized, max limits on stack, ... It would be nice if you could write recursive algorithms in code and be sure it ran as well and efficient as when you do it manually with for loops and separate stack data structures.
That's a feature, not a bug, in my opinion. Recursion preserves information about the function's execution. The problem is debuggers being too dumb to detect it and present it well.
Imperative programmers learn special purpose constructs like loops that only work in simple cases. But since they are so wedded to them, they only reach for the more general tool in more complicated cases. Thus they blame the general tool for the complication.
Just do away with the special cases, and us eg functional calls as the basis for your control flow needs. Then recursion becomes simple.
If necessary, one can introduce loops as a special case later---if working with legacy code or languages that don't properly support function calls. (Eg languages without first class functions and tail call optimizations.)
Recursion is hard, but it is a fundamentally great tool.
If I talk to someone who doesn't understand programming, they can usually understand the if and for statements that you might find in food recipes or in legal contracts.
But almost nowhere outside mathematics and computer science (and certainly not as common as recipes) do you come across recursion.
It's mentally hard to think of a problem so that each step gets simpler.
Solving the towers of hanoi is not straight forward, I can't follow it at the speed that I can read as I could with basic math, I have to really think if what they are suggesting works and how does it work.
However when you get to solving hard problems, recursion really helps. I know from having spent hundreds of hours with interview questions. Bugs can make a problem go from taking me 30 minutes to 4+ hours. Where as using recursion and other functional programming concepts, once I got to the solution it would usually be bug free. So whereas it might not be as fast, I would be more confident in my final answer.
% Problem #2
% Each new term in the Fibonacci sequence is generated by
% adding the previous two terms. By starting with 1 and 2,
% the first 10 terms will be:
% 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, ...
% By considering the terms in the Fibonacci sequence whose
% values do not exceed four million, find the sum of the
% even-valued terms.
fibsum(_N,M,L) when M >= L -> 0;
fibsum(N,M,L) when M rem 2 =:= 0 -> M + fibsum(M, N + M, L);
fibsum(N,M,L) when M rem 2 =:= 1 -> fibsum(M, N + M, L).
problem_2(L) -> fibsum(1, 2, L) .
problem_2_test() -> ?assert(problem_2(100) =:= 44).
problem_2() -> problem_2(4000000) .
(When familiarizing myself with a new programming language I usually work through several 10's of the project Euler problems, that way I only have to learn one new thing.)
Is recursion difficult? I remember when we did our first recursion in the first year of CS and our professor told us it sould be hard. Then she went on a rant about divide and conquer which made little sense and eventually got to the bit about calling yourself until a criteria.
I think most of us thought it was the easiest part of that year.
I think recursion as an implementation is easy; recursion as a concept is hard to understand if you are just starting to learn. I think part of it is getting your mind to accept the notion that a thing can know of itself before itself has been fully defined.
Recursion is different. Almost in exactly the same way that geometric proofs are different.
As such, it requires different ways of teaching.
I have used "The Little Schemer" (even back when it was called "The Little Lisper") to teach lots of "non-programmers" (I hate that description) how to do recursion.
I don't think telling people who find a subject difficult that it is easy is very convincing.
Recursion seems fairly straightforward to me if you think about it in terms of how it's typically implemented (the stack and jumps), but that's not quite the mathematical way of thinking about it, I suppose.
Switching to using Erlang full time, closures and functional aspects (returning a function from a function) and recursion was a lot harder for me to grasp than the isolated processes and message passing.
It took a few months to get my head around it, but once you do, it becomes so obviously simple and easy that you start thinking in it directly. All of the sudden having to write "for(i=0;....)" seems eeky and cumbersome when going back to a language which doesn't handle recursion as well (where it will blow the stack for example).
> It took a few months to get my head around it, but once you do, it becomes so obviously simple and easy that you start thinking in it directly
This is exactly where functional programming shines, in my opinion. It gives you the ability to write your program logic directly, rather than use mechanical constructs (e.g. for loops with indexes) that behave as some logical construct.
The “for(i=0;...)” construct is something I’d give to a machine for the purpose of execution, whereas the logical description is how I’d explain it to a human — and the former can be deduced from the latter.
The concept of recursion was easiest to grasp by watching a kid do the maze on a placemat at a restaurant. You go in a line until you find a dead end, then backtrack. Repeat the process until you reach the goal. Each intersection where you make a decision is your function call, and each backtrack is the return result.
Which is an odd example, since maze solving by recursion typically requires something like the Zipper data structure. And... no, that is not necessarily easier to deal with than just using a standard stack and jotting down your work as you go.
The pseudocode will search the maze, find the exit, then print its location followed by the path to get there in reverse order. Nothing complicated, but shows off the statefulness of recursion without needing anything else.
And this is one where I find myself falling back onto (ironically, per the thread?) Dykstra's algorithm. Which I did not learn recursively. It makes much more sense because the "path" that I am recording is a first class thing in the algorithm and not a byproduct of the implementation.
I liked this. It reminds me of proof by induction. I recall my teacher telling us it was one of the harder concepts, and thinking, "this sounds just like recursion, and seems pretty natural." I think if she had taken away the scary introductory language, students would have been less afraid of it.
Recursion only begins with the notion of mutual recursion. Transforming imperative loops into recursion (with the constant-space accumulation pattern and TCO) is a nothing-special mechanical operation. Recursion really shines in mutually recursive algorithms, like the famous Hanoi Tower solution.
I think a good analogy to teach recursion are humans, or really any living thing, since they too are functions that call themselves. That is, each time you create a new human, it's function is to create a new human, and so on ad infinitum.
IMHO, the first problem of summing a generalized array of numerical elements is not best solved recursively. I suggest sum(flatten( )) is better and uses less overhead. The subsequent problems under discussion more strongly require recursion.
well I do not think recursion is difficult. but I think doing it in a tail-called optimised way, can sometimes be tricky (especially in compilers or node traversals).
that's why more and more cps style recursion comes into place more than often. heck even scala has a way to do cps style tail calls: https://www.scala-lang.org/api/current/scala/util/control/Ta...
Didn't read the article. I usually don't have trouble with recursion, however lately I have started to avoid it more and more often. It is true that linear solutions usually look more complex. However in my opinion they also allow better reuse of local variables. Their complexity also depends on the datastructure. Designing a linear datastructure for nested problems is sometimes possible and can allow simple non-recursive solutions which I find more elegant.
The easiest way to learn recursion imo is by limiting the domain.
For example, we have a thing called a number:
x
how do we indicate the next number? Well we need a new symbol to distinguish one number from another.
Lets use a marker called prime:
x, x`
Great, now we have two numbers. But let's get a third number. How could we indicate that? Well we could introduce a totally new symbol, like a 'q'.
x, x`, q.
Well that works. but we seem to have just arbitrarily chosen q. There's no immediate obvious aspect of q that lets us know what the next symbol should be if someone asked us to add yet another number. We have three distinct number things but no clear unified way to proceed... But wait, before we took some number x and added a prime to it:
x->x`
which got us a separate symbol, aka a different number. What if we just do that again but this time with our second number:
x`->x``
Great. Now we have three numbers, and we can always use the same rule "add a prime mark" to generate the next symbol, so long as we input the last symbol into our rule:
x, x`, x``
We also wind up with neat little equivalences:
x`` = x`, x = x, x, x
or if our prime operation is a function:
x`` = prime(prime(x)) = prime(x`) = x``
so x``, is just the result of prime of prime of x.
So on and so forth until infinity.
What makes recursion harder to work with in CS is that, unlike summation, you can't go to infinity--you need to terminate the operation eventually if you actually want it to do anything. Because of this and because of the fact that our inputs are not little units like numbers but are usually data structures which require more rules to recurse over, recursion in CS is tightly and innately coupled with pattern matching and the notion of defining bottoms or terminating cases which is not the case for operations in mathematics where we do not care about terminating because it just encodes the rule and isn't actually meant to do anything, and when we do need to do something with it we limit it by deciding when to stop (so I guess some neuron firing is the bottom/terminating case for human operations?).
Recursion in CS is also additionally difficult because we have to worry about how the computer stores the results of each recursive application and feeds them back whereas, kind of like a high level language, our brain just manages all that for us when we do math. Also note that we take huge shortcuts with things like Arabic numerals--which are an incredible advance in efficiency but probably obfuscate the recursive roots of mathematics for most learners (e.g. you just learn that some symbol 2 and some symbol 2 is another symbol 4 and not that these are encapsulating successive applications of the same rule over a set of arbitrary symbols--I mean, your brain knows this deep down--that's why it works, but it makes it difficult to immediately comprehend that it is in fact recursive unless people have pointed this out to you--at least that was my experience; I may have just had bad teachers).
"This article is aimed to introduce and explain a number of topics and ideas that will help you when practicing recursive problems."
I know I'm not supposed to shit talk the article. I know someone spent a lot of time making it for me and others. However, we've gotta move forward as a community. We have to raise the bar. We have to stop this nonsense.
There is an issue here greater than recursion. I know that's bold of me to say, but I'm serious. Programmers need STOP fucking telling people that they can explain something that requires practice to understand. You cannot learn multiplication from reading a blog post. It has to be drilled into you over and over again. And only after it's been drilled into you what numbers are, what addition and subtraction are, and what carrying and borrowing mean. You learn this over the course of YEARS not 5 minutes reading some shitpost on the internet. Recursion is just like math. It has to be drilled into you. I had zero understanding of this for YEARS. And then I picked up a book that drills recursion into you. Only after writing function after function (functions essentially identical to one another in structure), was I able to understand the IMPORTANCE of recursion. Not by thinking about it, or reasoning about it, by actually doing it, over and over again. Recursion can be explained in 10 seconds. I'll do it right now. Recursion is when a set of instructions starts over from step 1. Or for us programmers, a function which calls itself. Bam. all you need to know about recursion. Guess what. It's not enough to understand what multiplication is, you actually have to be able to use it. You actually have to be able to use recursion. Explaining why multiplication is important is frankly retarded. This post is frankly retarded. STOP pretending that you can explain in 5 minutes what took you months and years to understand. STOP. All you do is make people like me think they're dumb for not getting it. I'M SMARTER THAN YOU! But it took me months of ACTUALLY WRITING RECURSIVE FUNCTIONS to realize HOW FUCKING DUMB YOU ALL ARE. Stop fucking telling people you can teach them calculus in 5 minutes. Stop telling them that all it takes is this one clear explanation. It doesn't! It takes actual work. Fuck the guy who wrote that post. You have no idea how many years I wasted thinking blog posts like this were how to learn. If you don't get why recursion is a big deal, do yourself a favor and forget everything you read in that post, grab a pencil, some paper, and a copy of the Little Lisper. Email me in 6 months when you're finished, so that you can thank me for being the only one to tell you the truth about recursion.
Recursion isn't difficult. I never had a problem understanding it. Stepping through a recursive function with a debugger that shows you the current stack trace should make it plain as day how it works.
Not trying to toot my own horn or try to make an appearance on /r/iamverysmart, but where are people struggling when it comes to understanding recursion?
I never had trouble, but a lot of my friends really did. I helped a lot of them, and I generally got the impression that the ones that really struggled were the ones that fundamentally didn't understand how function calls and returning values truly worked.
Like if you just were to do something like
`foo(bar(yuk(asdf(value)))).bind(reck(something)).toString()`
(not that this is a reasonable example), they'd have trouble tracing the order of execution. This was freshman year, so I'm sure they're all fine now, but CS is so abstract that every new concept has a barrier that can be surprisingly hard to overcome. Things like recursion or `this` may seem obvious now, but they weren't always.
> I generally got the impression that the ones that really struggled were the ones that fundamentally didn't understand how function calls and returning values truly worked.
You're probably right.
I don't think in the entire time I was in school, we were shown a debugger and how to read a stack trace or step through code. In one of my classes, we might have glossed over it for a couple minutes, but generally there was very little real debugging shown. It was always "Oh, we didn't get the expected result, let's look harder at the code we've entered." My school may have offered a class on debuggers as an elective or maybe a Masters level class.
Really though, using a debugger, even if it's just the one in Visual Studio, should be included in the first-year classes. By the end of your first year, you should be able to know what a stack trace is and what it's telling you.
I remember one of the books in my algorithms class actively discouraged debuggers and advocated for harder reasoning and inserting print statements. Their reasoning was that programmes are too quick to reach for a debugger rather than really understanding their code. I'm still not sure how I feel about that.
If you were trying to learn math, your shouldn't be reaching for a calculator everytime when there's a difficult arithmetic problem.
A debugger is the same. Use it when you've mastered skill of desk checking code, and understand how to make hypothesis about where bugs might be and binary search with prints to debug.
When actually developing software, you then reach for the debugger for convenience. But the skills learnt above is still very useful, and is in fact a good way to learn how to problem solve.
If you only ever relied on a debugger, it'd be like only knowing how to use calculator and no mental arithmetic.
I remember when I was learning recursion that I didn't get it for a while until it just clicked and made sense one day. It's hard to remember what it was like not getting it, but I think that a large part of it was not trusting that the recursive call would return the right thing. Eventually, by just encountering more problems in class where it was needed, it just clicked. I think it's that lack of trust that gets a lot of people tripped up.
{kind=link}
Would suggest instead something like
"We could solve this directly by managing our own stack of work done and keeping track of where we are in the problems as we divide them up, but it's easier to take advantage of the fact that the programming language is already providing us a call stack that can do this work for us."
Then, later, you can point out that this also helps with the backtracking solution as the programming language is maintaining the old environments; if you were iteratively managing your own stack you'd also have to backtrack manually.
Because that's how you transform a recursive call into an iterative one, not nested for loops. The general points made in the article still hold up, of course.