I’ve been “testing” LLM willingness to explore novel ideas/hypotheses for a few random topics[0].
The earlier LLMs were interesting, in that their sycophantic nature eagerly agreed, often lacking criticality.
After reducing said sycophancy, I’ve found that certain LLMs are much more unwilling (especially the reasoning models) to move past the “known” science[1].
I’m curious to see how/if we can strike the right balance with an LLM focused on scientific exploration.
[0]Sediment lubrication due to organic material in specific subduction zones, potential algorithmic basis for colony collapse disorder, potential to evolve anthropomorphic kiwis, etc.
[1]Caveat, it’s very easy for me to tell when an LLM is “off-the-rails” on a topic I know a lot about, much less so, and much more dangerous, for these “tests” where I’m certainly no expert.
1,500 tool calls per task sounds like a nightmare for unit economics though. I've been optimizing my own agent workflows and even a few dozen steps makes it hard to keep margins positive, so I'm not sure how this is viable for anyone not burning VC cash.
True, but that's still 1,500 inference cycles. Even without external API fees, the latency and compute burden seems huge. I don't see how the economics work there without significant subsidies.
An LLM model only outputs tokens, so this could be seen as an extension of tool calling where it has trained on the knowledge and use-cases for "tool-calling" itself as a sub-agent.
Sort of. It’s not necessarily a single call. In the general case it would be spinning up a long-running agent with various kinds of configuration — prompts, but also coding environment and which tools are available to it — like subagents in Claude Code.
> People have said that software engineering at large tech companies resembles "plumbing"
> AI code [..] may also free up a space for engineers seeking to restore a genuine sense of craft and creative expression
This resonates with me, as someone who joined the industry circa 2013, and discovered that most of the big tech jobs were essentially glorified plumbers.
In the 2000s, the web felt more fun, more unique, more unhinged. Websites were simple, and Flash was rampant, but it felt like the ratio of creators to consumers was higher than now.
With Claude Code/Codex, I've built a bunch of things that usually would die at a domain name purchase or init commit. Now I actually have the bandwidth to ship them!
This ease of dev also means we'll see an explosion in slopware, which we're already starting to see with App Store submissions up 60% over the last year[0].
My hope is that, with the increase of slop, we'll also see an increase in craft. Even if the proportion drops, the scale should make up for it.
We sit in prefab homes, cherishing the cathedrals of yesteryear, often forgetting that we've built skyscrapers the ancient architects could never dream of.
More software is good. Computers finally work the way we always expected them to!
> joined the industry circa 2013, and discovered that most of the big tech jobs were essentially glorified plumbers
Most tech jobs are glorified plumbers. I've worked in big tech and in small startups, and most of the code everywhere is unglamorous, boring, just needs to be written.
Satisfaction with the job also depends on what you want out of it. I know people who love building big data pipelines, and people who love building fancy UIs. Those two groups would find the other's job incredibly tedious.
The right job for a person depends on whether they can rise above the specific flavor of pain that the job dishes out. BigTech jobs strike me as having an inextricable political element to them: so you enjoy jockeying for titles and navigating constant reorgs?
The pay is nice but I find myself…remarkably unenvious as I get older.
Big companies are political and re-orgs lead to layoffs. Startups are a constant battle for funding and go out of business. Small companies mean a lot of exposure to bad management and budget issues. Charities are highly regulated and audited environments. Government jobs have no perks and entrenched middle management.
Every type of work has its idiosyncrasies, which people will either get on with or not. Mentioning one without the others is a bit disingenuous, or its whatever the opposite of the grass-is-greener bias is.
Plumbing has certification and industry best practices, and its leaks generally affect a few blocks at most rather than spraying across the entire internet.
Er... we sit in prefab homes? Trailers are generally considered to be the worst possible quality of home construction and actually lose value instead of the normal appreciation real estate has.
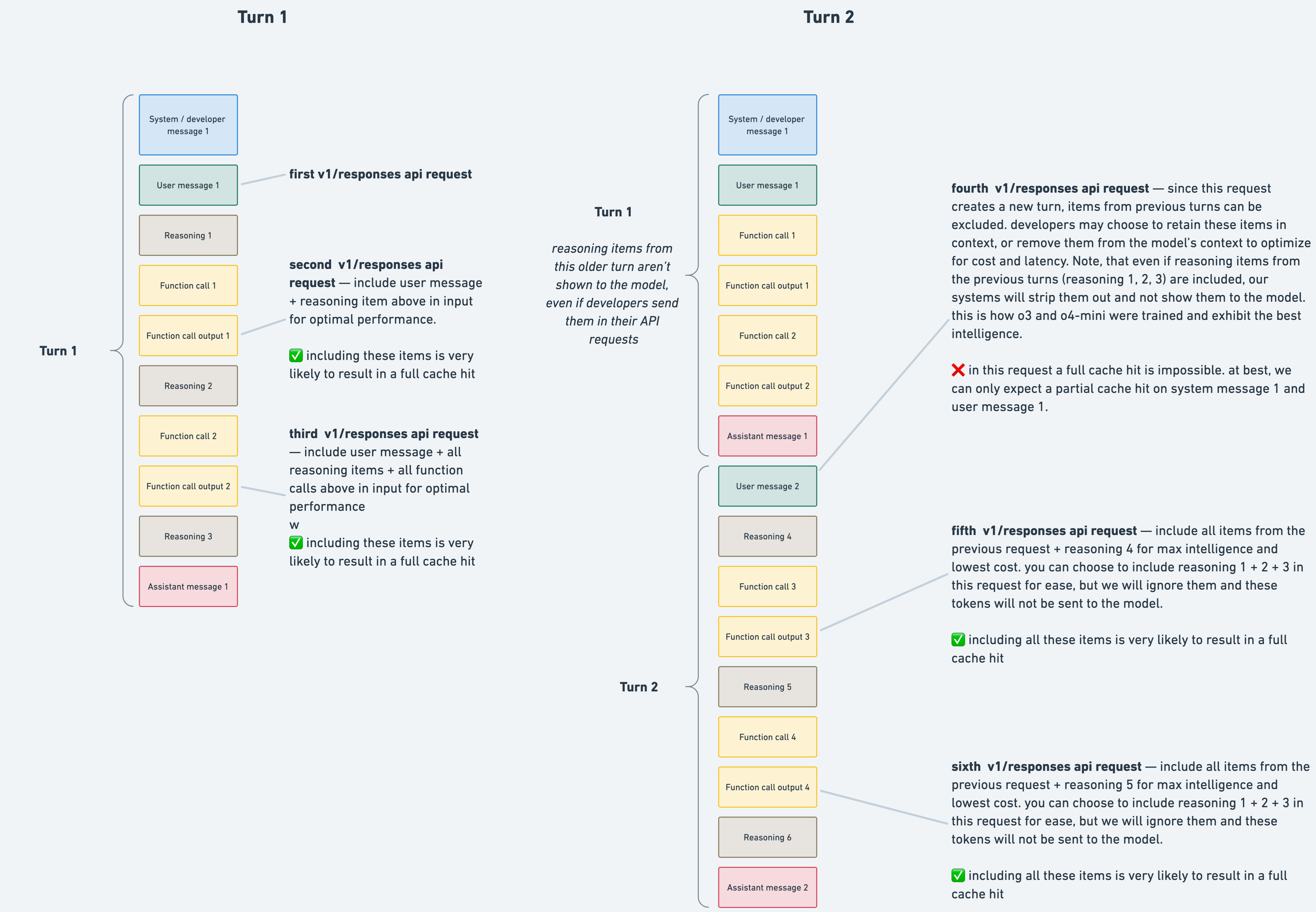
One thing that surprised me when diving into the Codex internals was that the reasoning tokens persist during the agent tool call loop, but are discarded after every user turn.
This helps preserve context over many turns, but it can also mean some context is lost between two related user turns.
A strategy that's helped me here, is having the model write progress updates (along with general plans/specs/debug/etc.) to markdown files, acting as a sort of "snapshot" that works across many context windows.
I'm pretty sure that Codex uses reasoning.encrypted_content=true and store=false with the responses API.
reasoning.encrypted_content=true - The server will return all the reasoning tokens in an encrypted blob you can pass along in the next call. Only OpenaAI can decrypt them.
store=false - The server will not persist anything about the conversation on the server. Any subsequent calls must provide all context.
Combined the two above options turns the responses API into a stateless one. Without these options it will still persist reasoning tokens in a agentic loop, but it will be done statefully without the client passing the reasoning along each time.
Maybe it's changed, but this is certainly how it was back in November.
I would see my context window jump in size, after each user turn (i.e. from 70 to 85% remaining).
Built a tool to analyze the requests, and sure enough the reasoning tokens were removed from past responses (but only between user turns). Here are the two relevant PRs [0][1].
When trying to get to the bottom of it, someone from OAI reached out and said this was expected and a limitation of the Responses API (interesting sidenote: Codex uses the Responses API, but passes the full context with every request).
This is the relevant part of the docs[2]:
> In turn 2, any reasoning items from turn 1 are ignored and removed, since the model does not reuse reasoning items from previous turns.
Thanks. That's really interesting. That documentation certainly does say that reasoning from previous turns are dropped (a turn being an agentic loop between user messages), even if you include the encrypted content for them in the API calls.
I wonder why the second PR you linked was made then. Maybe the documentation is outdated? Or maybe it's just to let the server be in complete control of what gets dropped and when, like it is when you are using responses statefully? This can be because it has changed or they may want to change it in the future. Also, codex uses a different endpoint than the API, so maybe there are some other differences?
Also, this would mean that the tail of the KV cache that contains each new turn must be thrown away when the next turn starts. But I guess that's not a very big deal, as it only happens once for each turn.
> And here’s where reasoning models really shine: Responses preserves the model’s reasoning state across those turns. In Chat Completions, reasoning is dropped between calls, like the detective forgetting the clues every time they leave the room. Responses keeps the notebook open; step‑by‑step thought processes actually survive into the next turn. That shows up in benchmarks (TAUBench +5%) and in more efficient cache utilization and latency.
I think the delta may be an overloaded use of "turn"? The Responses API does preserve reasoning across multiple "agent turns", but doesn't appear to across multiple "user turns" (as of November, at least).
In either case, the lack of clarity on the Responses API inner-workings isn't great. As a developer, I send all the encrypted reasoning items with the Responses API, and expect them to still matter, not get silently discarded[0]:
> you can choose to include reasoning 1 + 2 + 3 in this request for ease, but we will ignore them and these tokens will not be sent to the model.
> I think the delta may be an overloaded use of "turn"? The Responses API does preserve reasoning across multiple "agent turns", but doesn't appear to across multiple "user turns" (as of November, at least).
It depends on the API path. Chat completions does what you describe, however isn't it legacy?
I've only used codex with the responses v1 API and there it's the complete opposite. Already generated reasoning tokens even persist when you send another message (without rolling back) after cancelling turns before they have finished the thought process
Also with responses v1 xhigh mode eats through the context window multiples faster than the other modes, which does check out with this.
That’s what I used to think, before chatting with the OAI team.
The docs are a bit misleading/opaque, but essentially reasoning persists for multiple sequential assistant turns, but is discarded upon the next user turn[0].
The diagram on that page makes it pretty clear, as does the section on caching.
I think it might be a good decision though, as it might keep the context aligned with what the user sees.
If the reasoning tokens where persisted, I imagine it would be possible to build up more and more context that's invisible to the user and in the worst case, the model's and the user's "understanding" of the chat might diverge.
E.g. image a chat where the user just wants to make some small changes. The model asks whether it should also add test cases. The user declines and tells the model to not ask about it again.
The user asks for some more changes - however, invisibly to the user, the model keeps "thinking" about test cases, but never telling outside of reasoning blocks.
So suddenly, from the model's perspective, a lot of the context is about test cases, while from the user's POV, it was only one irrelevant question at the beginning.
This is effective and it's convenient to have all that stuff co-located with the code, but I've found it causes problems in team environments or really anywhere where you want to be able to work on multiple branches concurrently. I haven't come up with a good answer yet but I think my next experiment is to offload that stuff to a daemon with external storage, and then have a CLI client that the agent (or a human) can drive to talk to it.
worktrees are good but they solve a different problem. Question is, if you have a lot of agent config specific to your work on a project where do you put it? I'm coming around to the idea that checked in causes enough problems it's worth the pain to put it somewhere else.
## Task Management
- Use the projects directory for tracking state
- For code review tasks, do not create a new project
- Within the `open` subdirectory, make a new folder for your project
- Record the status of your work and any remaining work items in a `STATUS.md` file
- Record any important information to remember in `NOTES.md`
- Include links to MRs in NOTES.md.
- Make a `worktrees` subdirectory within your project. When modifying a repo, use a `git worktree` within your project's folder. Skip worktrees for read-only tasks
- Once a project is completed, you may delete all worktrees along with the worktrees subdirectory, and move the project folder to `completed` under a quarter-based time hierarchy, e.g. `completed/YYYY-Qn/project-name`.
More stuff, but that's the basics of folder management, though I haven't hooked it up to our CI to deal with MRs etc, and have never told it that a project is done, so haven't ironed out whether that part of the workflow works well. But it does a good job of taking notes, using project-based state directories for planning, etc. Usually it obeys the worktree thing, but sometimes it forgets after compaction.
I'm dumb with this stuff, but what I've done is set up a folder structure:
And then in dev/AGENTS.md, I say to look at ai-workflows/AGENTS.md, and that's our team sharable instructions (e.g. everything I had above), skills, etc. Then I run it from `dev` so it has access to all repos at once and can make worktrees as needed without asking. In theory, we all should push our project notes so it can have a history of what changed when, etc. In practice, I also haven't been pushing my project directories because they have a lot of experimentation that might just end up as noise.
worktrees are a bunch of extra effort. if your code's well segregated, and you have the right config, you can run multiple agents in the same copy of the repo at the same time, so long as they're working on sufficiently different tasks.
I do this sometimes - let Claude Code implement three or four features or fixes at the same time on the same repository directory, no worktrees. Each session knows which files it created, so when you ask CC to commit the changes it made in this session, it can differentiate them. Sometimes it will think the other changes are temporary artifacts or results of an experiment and try to clear them (especially when your CLAUDE.md contains an instruction to make it clean after itself), so you need to watch out for that. If multiple features touch the same file and different hunks belong to different commits, that's where I step in and manually coordinate.
I'm insane and run sessions in parallel. Claude.md has Claude committing to git just the changes that session made, which lets me pull each sessions changes into their own separate branch for review without too much trouble.
that's the main gripe I have with codex; I want better observability into what the AI is doing to stop it if I see it going down the wrong path. in CC I can see it easily and stop and steer the model. in codex, the model spends 20m only for it to do something I didn't agree on. it burns OpenAI tokens too; they could save money by supporting this feature!
I’ve been using agent-shell in emacs a lot and it stores transcripts of the entire interaction. It’s helped me out lot of times because I can say ‘look at the last transcript here’.
It’s not the responsibility of the agent to write this transcript, it’s emacs, so I don’t have to worry about the agent forgetting to log something. It’s just writing the buffer to disk.
Same here! I think it would be good if this could be made by default by the tooling. I've seen others using SQL for the same and even the proposal for a succinct way of representing this handoff data in the most compact way.
That could explain the "churn" when it gets stuck. Do you think it needs to maintain an internal state over time to keep track of longer threads, or are written notes enough to bridge the gap?
Sonnet has the same behavior: drops thinking on user message. Curiously in the latest Opus they have removed this behavior and all thinking tokens are preserved.
but that's why I like Codex CLI, it's so bare bone and lightweight that I can build lots tools on top of it. persistent thinking tokens? let me have that using a separate file the AI writes to. the reasoning tokens we see aren't the actual tokens anyway; the model does a lot more behind the scenes but the API keeps them hidden (all providers do that).
Codex is wicked efficient with context windows, with the tradeoff of time spent. It hurts the flow state, but overall I've found that it's the best at having long conversations/coding sessions.
It's worth it at the end of the day because it tends to properly scope out changes and generate complete edits, whereas I always have to bring Opus around to fix things it didn't fix or manually loop in some piece of context that it didn't find before.
That said, faster inference can't come soon enough.
> That said, faster inference can't come soon enough.
why is that? technical limits? I know cerebras struggles with compute and they stopped their coding plan (sold out!). their arch also hasn't been used with large models like gpt-5.2. the largest they support (if not quantized) is glm 4.7 which is <500B params.
where do you save the progress updates in? and do you delete them afterwards or do you have like 100+ progress updates each time you have claude or codex implement a feature or change?
I ran the Gas Town intro post through ChatGPT 5.2 Pro[0]
Based on my initial read, and a pass at this summary, it seems mostly right. YMMV
Did some further dives into the little public usage data from Gas Town, and found that most of the "Beads" are tasks that are broken down quite small, almost too small imo.
Super interesting project with the goal of keeping Claude "busy" however it feels more like a casino game than something I'd use for production engineering.
I’ve found that experienced devs use agentic coding in a more “hands-on” way than beginners and pure vibe-coders.
Vibecoders are the best because they push the models in humorous and unexpected ways.
Junior devs are like “I automated the deploy process via an agent and this markdown file”
Seasoned devs will spend more time writing the prompt for a bug fix, or lazily paste the error and then make the 1-line change themselves.
The current crop of LLMs are more powerful than any of these use cases, and it’s exciting to see experienced devs start to figure that out (I’m not stanning Gas Town[0], but it’s a glimpse of the potential).
Partially related: I really dislike the vibe of Gas Town, both the post and the tool, I really hope this isn't what the future looks like. It just feels disappointing.
To be fair, the author says: "Do not use Gas Town."
I started "fully vibecoding" 6 months ago, on a side-project, just to see if it was possible.
It was painful. The models kept breaking existing functionality, overcomplicating things, and generally just making spaghetti ("You're absolutely right! There are 4 helpers across 3 files that have overlapping logic").
A combination of adjusting my process (read: context management) and the models getting better, has led me to prefer "fully vibecoding" for all new side-projects.
Note: I still read the code that gets merged for my "real" work, but it's no longer difficult for me to imagine a future where that's not the case.
I have noticed in just the past two weeks or so, a lot of the naysayers have changed their tunes. I expect over the next 2 months there will be another sea change as the network effect and new frameworks kick in.
No. If anything we are getting "new" models but hardly any improvements. Things are "improving" on scores, ranking and whatever other metrics the AI industry has invented but nothing is really materializing in real work.
I think we have crossed the chasm and the pragmatists have adopted these tools because they are actually useful now. They've thrown out a lot of their previously held principles and norms to do so and I doubt the more conservative crowd will be so quick to compromise.
2 years sounds more likely than 2 months since the established norms and practices need to mature a lot more than this to be worthy of the serious consideration of the considerably serious.
Curious what fidelity/precision the author finds necessary with Claude 4.5 Opus/GPT 5.2.
Looking at the screenshot of "Tracked Issues", it seems many of the "tasks" are likely overlapping in terms of code locality.
Based on my own experience, I've found the current crop of models to work well at a slightly higher-level of complexity than the tasks listed there, and they often benefit from having a shared context vs. when I've tried to parallelize down to that level of work (individual schema changes/helper creation/etc.).
Maybe I'm still just unclear on the inner workings, but it's my understanding each of those tasks is passed to Claude Code and developed separately?
In either case, I think this project is a glimpse into the future of software development (albeit with a grungy desert punk tinted lens).
For context, I've been "full vibe-coding"[0] for the past 6 months, and though it started painfully, the models are now good enough that not reading the code isn't much of an issue anymore.
{kind=link}
The earlier LLMs were interesting, in that their sycophantic nature eagerly agreed, often lacking criticality.
After reducing said sycophancy, I’ve found that certain LLMs are much more unwilling (especially the reasoning models) to move past the “known” science[1].
I’m curious to see how/if we can strike the right balance with an LLM focused on scientific exploration.
[0]Sediment lubrication due to organic material in specific subduction zones, potential algorithmic basis for colony collapse disorder, potential to evolve anthropomorphic kiwis, etc.
[1]Caveat, it’s very easy for me to tell when an LLM is “off-the-rails” on a topic I know a lot about, much less so, and much more dangerous, for these “tests” where I’m certainly no expert.