I don't see why you'd choose Go instead of a JVM language like Java, you get the language simplicity (plus features like Generics) and the performance upside too.
But setup a java toolchain, building, deploying, and a lot of other configuration if some heavy framework is involved, is non-trivial. Gradle is like a must for modern Java application, and mastering itself takes some efforts. Go, when coming to toolchain, it is pretty much battery-included, best-practice-builtin, sometimes even a little forced.
Language wise, Java recently has seem a more aggressive adoption of new and modern features, which is quite welcome for me personally, but it is still more LOC comparing to Go.
I think Go is the new Python for light to middle complexity web service, with fewer people. Java is more for mature stuff, for larger scale collaboration.
A build.gradle file that lists a few dependencies is like maybe 7 or 8 lines of code, which can almost all be cargo culted. You only need to start consulting the Gradle manual once you start doing things like defining custom build tasks or wanting to use custom plugins.
Go's toolchain doesn't even bother with versioning. That's like the opposite of batteries-included, forced-best-practices. But of course it will seem simpler than a tool that does handle these basic things.
If you want the benefits of Java with a lighter syntax then look at Kotlin.
> A build.gradle file that lists a few dependencies is like maybe 7 or 8 lines of code, which can almost all be cargo culted
...and that code is written in Apache Groovy. Strange why they'd bundle a Turing-complete scripting language for their build file DSL when it's only 7 or 8 lines long.
My experience is the exact opposite: Go takes more lines to do something than Java.
I would say that in large part, this is because the error handling restricts expressions to a rather small size, and then because without streams, collection manipulation has to be written out longhand.
I agree with you on the error handling part, although it is not a big pain for me yet.
But in terms of parallel programming, when doing in Java, I constantly find myself basically building a lot of stuff where Go has as a part of its own semantic. Queues -> Channel, Executors -> M in Go, and Runnables -> Go functions. Java8's Lambada and ForkJoinPool is an advance in the right direction but still not quite there.
Language simplicity? I disagree, Java is only agreable if you're comfortable with (1) being forced to work in an OOP-only environment and (2) using the JVM. And while you can argue for the upsides of both of these (which I believe are few and far between) they certainly add a great deal of clunky complexity, which many programmers are fleeing to Golang to avoid.
If popular Java toolchains are the most complex you can imagine, I assume you have never encountered autotools, or really any toolchain for a large C++ project.
Toolchains normally mean build systems, debuggers, profilers, editors and other things.
Java itself doesn't require any build tool at all, you could do it all with a custom shell script. The next step up after that is an IDE like IntelliJ where you press "new project" and just start writing code. The IDE's build system will do it all for you. There is no complexity.
But most people want features like dependency management, IDE independence, command line builds, ability to customise the build with extra steps and so on. That's when you upgrade to something like Gradle (or maybe Maven if you like declarative XML). That'll give you dependency resolution with one-line-one-dependency, versioning, automatic downloads, update checking and other useful features. Many IDEs can create a Gradle project for you.
When I first encountered Java it seemed the most popular build tool was Maven, which looked very over complex at first due to its poor docs and love of inventing new words, but pretty quickly found that it wasn't so bad in reality. Gradle avoids the custom dictionary and uses a much lighter weight syntax. It's pretty good.
>If popular Java toolchains are the most complex you can imagine, I assume you have never encountered autotools, or really any toolchain for a large C++ project.
The point was about Java, so I was responding to that, but yes, I steer clear of C++ (when possible) for the same reason.
> Gradle [...] give you dependency resolution with one-line-one-dependency, versioning, automatic downloads, update checking and other useful features.
I don't see your point. If you have a collection of source files, then something must search the directory tree to find them and feed them to the compiler ... ideally, only the files that have changed, to give fast incremental compilation.
If you use a typical Java IDE like IntelliJ then the program that does that will be the IDE. There is no "one more layer" because that's the first and only layer.
If the IDE build system does not provide enough features or you'd like your codebase to be IDE independent, you can also use a separate build tool, or a combination of both (in which case the IDE will sync itself to the other build tool).
In that case there are two layers. But Go does not have any magical solution to that. There will be Go apps that need more than the little command line tool can do as well.
Right, so then it is more complex than `go build`. QED.
To be clear, I'm not claiming that Go is "better"; I'm just pointing out that this is why one would chose Go over Java. Sometimes this particular benefit doesn't outweigh the costs relative to developing in Java, but language/toolchain simplicity remains -- nonetheless -- the reason why people prefer one over the other.
Yes, "gradle build" wants to see a "build.gradle" file in the current directory, but you can run "gradle init" to get one. And after that everything except specifying dependencies is by convention.
There's really little to no difference in complexity here. What Go saves by not having a build file it loses by not encoding enough information about dependencies in the source, which leads to horrible hacks like vendoring.
Nobody forces you to use a complex toolchain for Java. You can use javac and ed if you like. But Java is sufficiently simple and sufficiently popular for pretty awesome tooling to be available. Refactoring Java code is a breeze because your IDE understands the code perfectly.
A text editor, javac and java that's what I used for a few years when I started using it. I wrote a lot of code like that. I don't see why you couldn't?
> I remember the Go language specification to be about as long as the table of contents for the Java language specification.
I'm not sure where you got that from. On my browser and screen, the JLS8 TOC[0] is 16 pages high which brings me about 20% into the Go language spec[1].
But then again that's a completely inane appeal to emotions: because it's a specification for cross-platform and cross-implementation compatibility (not a user-targeted documentation):
* the JLS is exactingly precise, the JLS's "lexical structure" section is about 3 times longer than GoSpec's "Lexical Elements", the JLS's "Execution" section is about 6 times longer than GoSpec's "Program initialization and execution"
* the JLS contains entire sections which don't get a mention in GoSpec, like binary compatibility concern, or the language's entire execution model (calling a function gets a page in gospec, it gets 20+ in the JLS) and its multithreaded memory model
The JLS is longer because its goal is that you be able to reimplement a Java compiler and runtime just from it, it's Java's entire rulebook.
Go's language spec is a much fuzzier document targeted towards language users — much like e.g. Python's language reference — there is no way you can write a clean-slate implementation just from the language spec.
> Go's language spec is a much fuzzier document targeted towards language users — much like e.g. Python's language reference — there is no way you can write a clean-slate implementation just from the language spec.
That's not correct. The Go spec is designed to be a precise specification of the language, targeted at language implementers. Ian Lance Taylor (incidentally, the author of these generics proposals) wrote gccgo based on that spec. There have been a couple of other implementations based on that spec since.
The main Go compiler itself was implemented from that spec, too. The spec comes first.
You are absolutely right, it's a silly comparison. The Go language spec is indeed vague.
I did this comparison a while ago. It wasn't very accurate. The Go spec has probably changed. Unfortunately, it seems they don't keep older specs around(!) If I adjust the font size in the ToC of the JLS I get 23 pages and the Go Spec is 84 pages (27%). Not quite "about the same length", still.
I took a compiler course in university where we implemented a compiler for a subset of java 1.3 (I believe), and the next year I was a TA in the compiler course. I got to read the (older) JLS quite a lot. I do find Java to be a more complicated language than Go. This does not mean I find it simpler to write programs in Go (c.f. Brainfuck).
RoboVM is one that compiles AOT ARM binaries, it's intended for the iPhone but it runs on MacOS too.
Avian is a JIT compiling JVM but one which is much smaller than HotSpot. It has a mode where it statically links your JAR into the binary itself, so you get a single self contained executable. With ProGuard and other optimisations like LZMA compression built in, such binaries can be remarkably small. Try their example:
You can make an executable "fat jar" with Capsule. It has a little shell script prepended to the JAR which means you can run it like "chmod +x foo.jar; ./foo.jar"
You can do dead code elimination and other forms of LTO using ProGuard. Just watch out for code that uses reflection. Java 9 will include a less aggressive version of the same thing which performs various link time optimisations like deleting modules (rather than individual methods/fields), statically pre-computing various tables, and converting from JAR into a more optimised (but platform specific) format.
That tool can also bundle a JRE in with your app, giving you an "tar xzvf and run" deployment model. It's not a single file, but it makes little difference in practice. The same tool can build DEBs, RPMs, Mac DMGs and Windows EXE/MSI installers with a bundled and stripped JRE too.
I'm a big fan of Capsule, actually. My point was not that Java and the JVM ecosystem are terrible (I quite like them), but rather that there is a spectrum of size and complexity and that Go's static binaries seem to be on the simpler to build side of JARs and on the smaller side of JARs.
Also, I don't think there's much of a case to be made that bundling a JRE with your JAR is small, even though the tooling might be simple and it might resolve many deployment issues.
Putting a jar on your classpath works just like depending on a shared library but with much stronger compatibility guarantees and better chances for optimization.
Memory usage and as a consequence of that excessive GC pauses. I'm not looking at any JVM language again before they introduce value types in a couple of years (maybe).
I build soft real time simulation systems in Java. GC pauses haven't been a problem since 1.2 was released around 2000. Memory usage isn't a concern either for big applications, as there's not a lot of overhead in the runtime. There is the fact that one can't embed value types directly in objects, but I don't find that a problem in practice.
Then your experience is very different from mine and that of many other people who resort to all sorts of off-heap solutions and distributing stuff across multiple VMs. I guess it depends a lot on the specific use case.
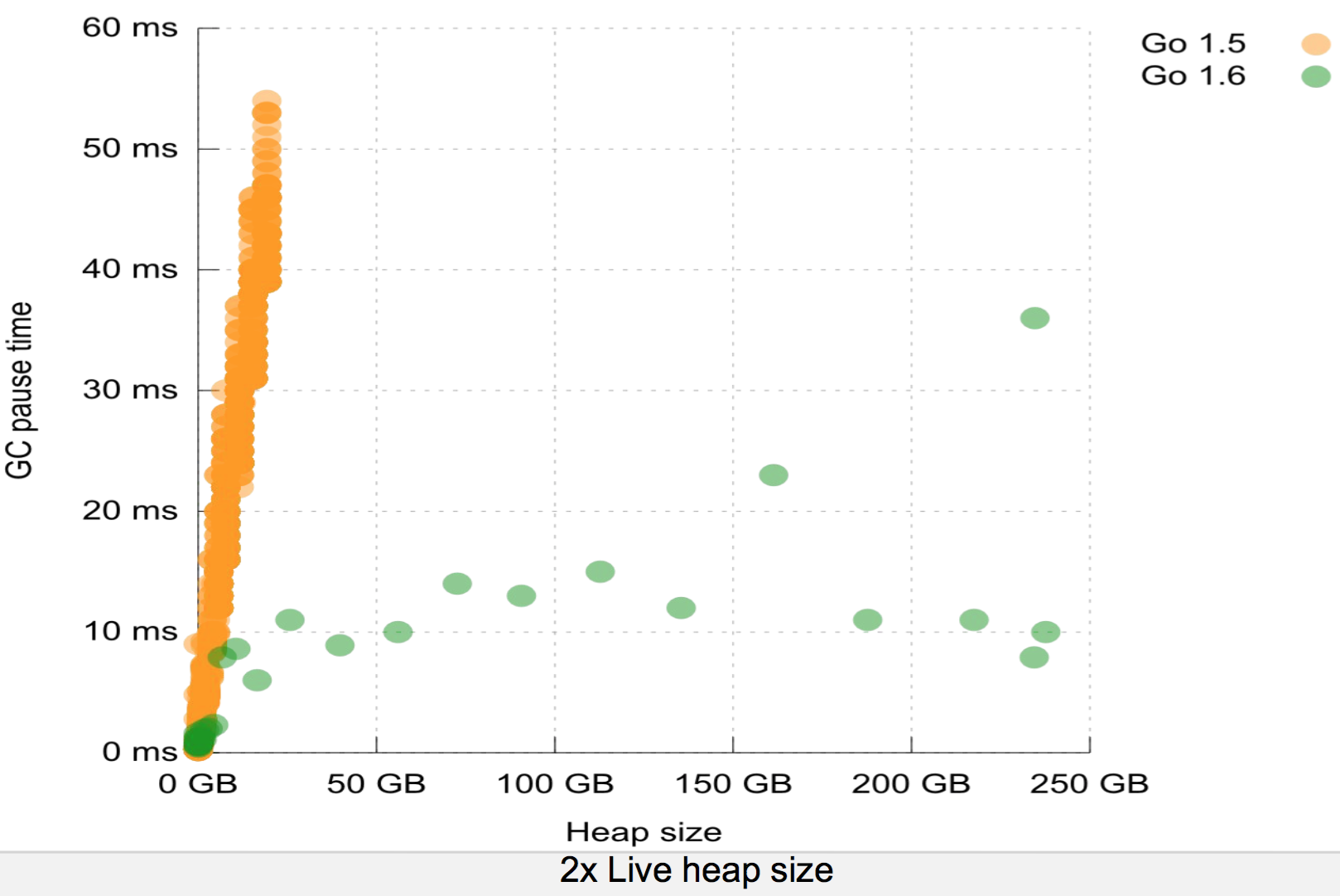
You can get 10msec pauses or less with heaps >100GB with HotSpot if you tune things well and use the latest GC (G1).
If you want no GC pauses at all, ever, well, Go can't do that either. But if you are willing to pay money to Azul, you can buy a JVM that can. It also concurrently compacts the heap, which Go's GC does not.
The issue is not Java. The issue is the quality of freely available garbage collectors, which are very good, but not pauseless.
>You can get 10msec pauses or less with heaps >100GB with HotSpot if you tune things well and use the latest GC (G1).
For what percentile of collections? I'm not wasting my time with incessant GC tuning only to delay that 5 minute stop the world pause for a bit longer. It's still going to hit eventually. For projects that might grow into that sort of heap size I use C++ (with an eye on Rust for the future).
You are right that Go is not a panacea for very large memory situations, but you can do a lot more before Go even needs that amount of memory.
The point is that languages without value types, such as Java and JavaScript, waste a huge amount of memory and generate a lot more garbage, thereby exacerbating all other related issues, including GC.
I have done quite a lot of testing for our workloads. Java memory usage is consistently two to three times higher than that of Go or C++. I'm unwilling to waste our money on that.
In a properly tuned system with sufficient CPU capacity there should never be any full GC pauses with G1.
To get 10msec pause times with such huge heaps requires burning a LOT of CPU time with the standard JDK collectors because they can trade off pause latency vs CPU time.
This presentation shows tuning with 100msec as the target:
2. Older collectors like CMS (still the default) sometimes take long pauses, like 5 seconds (not 5 minutes).
3. The new GC (G1) must be explicitly requested in Java 8. The plan is for it to be the default in Java 9, but switching to a new GC by default is not something to be taken lightly. G1 is, theoretically, configurably by simply setting a target pause time (lower == better latency but more CPU usage). Doing so eliminated all the long pauses, but a few collections were still 400msec (10x improvement over CMS).
4. With tuning, less than 1% of collections were over 300 msec and 60% of pauses were below the target of 100 msec.
Given that the Go collector, even the new one, isn't incremental or compacting I would be curious how effective it is with such large heaps. It seems to be that a GC that has to scan the whole 100GB every time, even if it does so in parallel, would experience staggeringly poor throughput.
Value types will certainly be a big, useful upgrade.
>In a properly tuned system with sufficient CPU capacity there should never be any full GC pauses with G1.
So you use a language without value types that makes you pay for two or three times more memory than comparable languages, and then you spend your time re-tuning the GC every time your allocation or usage patterns change. Then you hope to never trigger a full GC that could stall the VM for many seconds (or in extreme cases that I have seen even minutes). That makes very little sense to me.
I cannot speak to the performance of the current Go GC for 100G heap sizes. I never tried it and I haven't read anything about it. It's not my language of choice for that sort of task either.
They aren't comparable at all. Go doesn't collect incrementally and doesn't compact. So good luck collecting garbage fast enough to keep up with a heap-heavy app (which if you have a 100GB heap, your app probably is).
In other words, the issue is not pause time, it's also throughput.
But Go programs use way less memory than Java applications... so the java application that uses 100GB might only use 40GB (or less) in Go. And there are tweaks you can make to hot code in Go to not generate garbage at all (pooling etc).
Java's higher memory usage is not only related to value types, for example, in Java 8 strings always use 16 bit characters. That is fixed in Java 9. It resulted in both memory savings and speed improvements.
There are other sources of overhead too, but again - you seem to think Go has some magic solution to these problems. Since the new GC, Go is often using a heap much larger (such as twice the size) of actual live data. That's a big hit right there. And yes, you have to tune the Go GC:
Value types are the main culprit behind Java's insane memory consumption. I found out through weeks of testing and benchmarking.
I mostly benchmarked a small subset of our own applications and data structures. We use a lot of strings, so I never even started to use Java's String class, only byte[].
I tried all sorts of things like representing a sorted map as two large arrays to avoid the extra Entry objects. I implemented a special purpose b-tree like data structure. I must have tried every Map implementation out there (there are many!). I stored multiple small strings in one large byte[].
The point is, in order to reduce Java's memory consumption, you must reduce the number of objects and object references. Nothing else matters much. It leads to horribly complex code and it is extremely unproductive. The most ironic thing about it is that you can't use Java's generics for any of it, because they don't work with primitives.
I also spent way too much time testing all sorts of off-heap solutions. At the end of the day, it's just not worth it. Using Go or C# (or maybe Swift if it gets a little faster) for small to medium sized heaps and C++ or Rust for the humungous sizes is a lot less work than making the JVM do something it clearly wasn't built to do.
But I think your conclusion is not quite right. I said above that pointer overhead is only one source of Java memory consumption, and pointed to (hah) strings as another source. You replied and said no, it's all pointers, followed by "I never even started using strings". Do you see why that approach will lead to a tilted view of where the overheads are coming from?
If your application is so memory sensitive that you can't use basic data structures like maps or strings then yes, you really need to be using C++ at that point.
In theory, especially once value types are implemented, it would be possible for a Java app to have better memory usage than an equivalent C++ app, as bytecode is a lot more compact than compiled code and the JVM can do optimisations like deduplicate strings from the heap (already). Of course how much that helps depends a lot on the application in question. But the sources of gain and loss are quite complex.
>You replied and said no, it's all pointers, followed by "I never even started using strings". Do you see why that approach will lead to a tilted view of where the overheads are coming from?
I see what you mean, but when I said that Java uses two or three times as much memory as Go or C++, I didn't include tons of UTF-16 strings either, assuming most people don't use as many strings as I do. If your baseline does include a large number of heap based Java String objects, the difference would be much greater than two or three times because strings alone would basically double Java's memory usage (or triple it if you store mostly short strings like words using the short string optimization in C++ for comparison)
>In theory, especially once value types are implemented, it would be possible for a Java app to have better memory usage than an equivalent C++ app, as bytecode is a lot more compact than compiled code
I'd love to see that theory :-) But let's say it was magic and the bytecode as well as the VM itself would require zero memory, any difference would still only be tens of MB. So it would be negligible if we're talking about heap sizes on the order of tens or hundereds of GB.
Yes, if your heap is huge then code size savings don't matter much. I used to work with C++ apps that were routinely hundreds of megabytes in size though (giant servers that were fully statically linked). So code size isn't totally ignorable either.
WRT the theory, that depends what the heap consists of.
Imagine an app where memory usage is composed primarily of std::wstring, for example, because you want fast access to individual characters (in the BMP) and know you'll be handling multiple languages. And so your heap is made up of e.g. some sort of graph structure with many different text labels that all point to each other.
The JVM based app can benefit from three memory optimisations that are hard to do in C++ ... compressed OOPs, string deduplication and on-the-fly string encoding switches. OK, the last one is implemented in Java 9 which isn't released yet, but as we're theorising bear with me :)
Compressed OOPs let you use 32 bit pointers in a 64 bit app. Actually in this mode the pointer values are encoded in a way that let the app point to 4 billion objects not bytes, so you can use this if your heap is less than around 32 gigabytes. So if your graph structure is naturally pointer heavy in any language and, say, 20 gigabytes, you can benefit from this optimisation quite a lot.
String deduplication involves the garbage collector hashing strings and detecting duplicates as it scans the heap. As a String object points to the character array internally, that pointer can be rewritten and the duplicates collected, all in the background. If the labels on your graph structure are frequently duplicated for some reason, this gives you the benefits of a string interning scheme but without the need to code it up.
Finally the on-the-fly character set switching means strings that can be represented as Latin1 in memory are, with 16 bit characters only used if it's actually necessary. If your graph labels are mostly English but with some non-Latin1 text mixed in as well, this optimisation could benefit significantly.
Obviously, as they are both Turing complete, the C++ version of the app could implement all these optimisations itself. It could use 32 bit pointers on a 64 bit build, it could do its own string deduplication, etc. But then you have the same problem as you had with off-heap structures in Java etc: sure, you can write code that way, but it's a lot more pleasant when the compiler and runtime do it for you.
The exact same information is collected by public transport systems where you have a pass which you top up with your credit card, if the authorities want access to this data they just get in touch with the transit authority. I hate it and avoid these systems where possible.
And now your messenger app needs a launcher, switcher, notification manager, search, per-app settings pages, etc. And maybe its own process model/scheduler, to prevent rogue apps from slowing down the messenger app. And apps within the messenger app now need to be cross-messenger-platform on top of being cross-webview-platform.
Look, I'm all for Zach writing about his experience, but I never see him mention the whole incident with Julie Ann Horvath which is what I understand to be the reason he was fired.
Is there a reason he can't talk about what happened there?
It seems like there is some namedropping here [1] too though I don't see anything explicitly tying them together. It may be hard to definitively know since it's an HR issue and generally separation agreements require both sides to keep quiet. (Non-disparagement clauses)
Per the article:
I’m still not fully certain why I got the axe; it was never made explicit to me. I asked other managers and those on the highest level of leadership, and everyone seemed be as confused as I was.
My best guess is that it’s Tall Poppy Syndrome, a phrase I was unfamiliar with until an Aussie told me about it. (Everything worthwhile in life I’ve learned from an Australian, basically.) The tallest poppy gets cut first.
In most parts of the US, no. Like the post says, "I don't like the shoes you're wearing today" is a perfectly legal reason to fire in an at-will state.
The only exception I'm aware of -- and why it's a great idea to get things in writing -- is in a couple of states it's possible to sue the employer if they said they'd do one thing and did another thing. Whether it's possible in your state, and whether it'd be worth the (both financial and emotional cost) of the legal proceedings, is something to talk to a lawyer about, though, and I am not one.
This exception is, by the way, the reason why employee handbooks and other company documents pretty much never explain specific procedures they'll use for correcting problems, other than a catch-all "may lead to termination". Putting a procedure in writing can lead to someone holding you to that procedure, and no well-advised company puts itself at that risk.
Anyone can make a suit. (I've been on the receiving end of a frivolous one where the employee was caught committing fraud and sued anyway.) Frequently it's just cheapest for everyone to settle. A court date with expensive lawyers can cost more than a month's salary.
The law generally doesn't require a reason or documentation unless the employee is a protected class. If you are still positive with your boss or the CEO, you can usually ask off-line if you've signed something that says you won't sue.
Ugh, I have a take home assignment from them to do, worried the same thing will happen to me :/ I don't want to waste the time if they don't get back to me..
Glassdoor removes negative reviews if you advertise with them. Also if you know the right people who work there (source: my current bosses friend from college works there, and he was bragging to me about how he got them to pull all our negative reviews. One of which I wrote).
{kind=link}